Table of Contents
How Real-Time Ops Intelligence Enables Faster Decisions
Unlock faster decision-making with real-time ops intelligence. Learn how to streamline operations, reduce errors, and minimize costs in high-transaction environments.
February 10, 2026

AB

What is real-time operational intelligence?
Real-time operational intelligence is the practice of converting live operational signals from transactions, API calls, queue states, and reconciliation events into ranked, actionable decisions in minutes rather than hours. It differs from standard monitoring in three ways: it unifies signals from all systems into one view, scores them by business impact rather than technical severity, and routes the result to a named owner with enough context to act immediately.
TL;DR - Real-time ops intelligence (RT-OI) helps teams decide faster by turning dispersed signals into a single, trusted decision layer: prioritized alerts, evidence-backed recommendations, and automated low-risk fixes. The result: fewer noisy pages, faster critical escalations, and more impact per person, not more people. This article gives practical steps, metrics, and a short playbook you can pilot in 4–8 weeks.
The problem: more work, not more clarity
In many businesses, especially BFSI and high-transaction domains the real cost is what happens between systems. Reconciliation mismatches, stuck disbursements, missed KYC flags and SLA breaches often go undetected for days. In one go-to example, companies routinely discover exceptions after ~48 hours, and mid-sized enterprises can leak ₹3–5 Cr per month because discovery and triage took too long. The result: missed revenue, regulatory risk and trust erosion.
The cost of detection delay is not linear. A stuck disbursement caught within one hour typically takes 10 to 15 minutes to resolve. The same exception discovered 24 hours later involves customer escalation, manual investigation, and in regulated environments, documentation requirements. That is a cost multiplier of 15 to 20 times for the same underlying issue. The ₹3 to 5 crore monthly leakage figure in mid-market BFSI operations consistently traces to this same root cause: detection and triage delays, not the exceptions themselves.
(If this figure is from Autonmis pilot data, cite it explicitly as: "Based on Autonmis pilot data across mid-market BFSI operations in India." First-party data cited as first-party is more credible with this audience than an uncited claim.)
These are not problems you fix by hiring more people. They’re problems you fix by turning scattered signals into a continuous, contextual decision stream, a single substrate where detection, prioritization and action happen in minutes, not days.
Checkout: How Operations Teams Stop Repeating the Same Fixes
What I mean by “real-time ops intelligence” (plainly)
Not a product name. Think of it as three capabilities wired together:
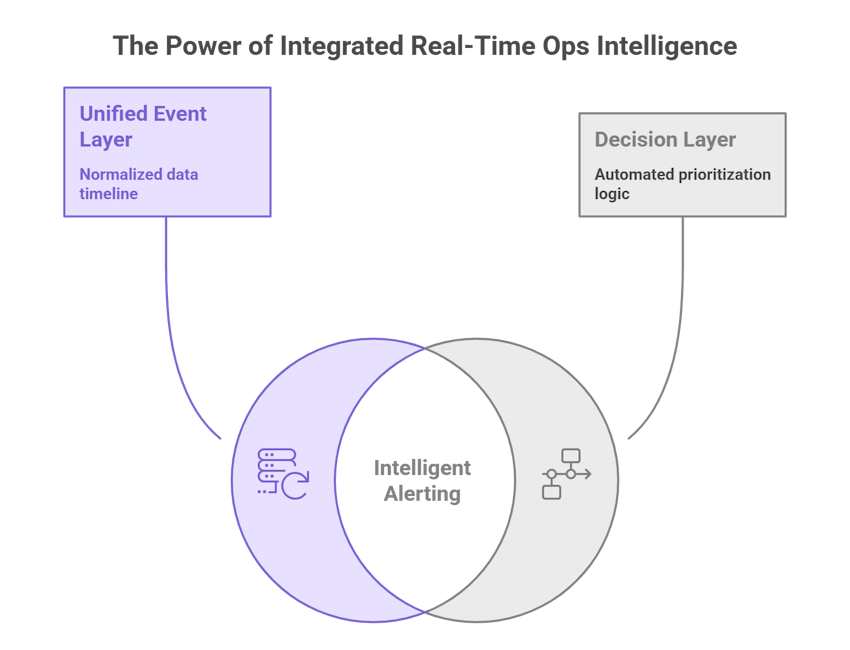
- Unified event layer: every transaction, API call, and reconciliation item is normalized into the same timeline.
- Decision layer: automated rules + prioritization logic that turn raw signals into ranked actions (e.g., “Escalate this high-value stuck disbursement now”).
- Action fabric: small automations and playbooks that either resolve trivial problems automatically or hand a clear, evidence-backed incident card to a human for a targeted fix.
The three capabilities only work as a system. A unified event layer without a decision layer creates a larger, noisier data store. A decision layer without an action fabric produces ranked lists that still require someone to manually find the right person and open a ticket. An action fabric without a unified event layer operates on incomplete information. When all three work together, an exception that previously sat in data for 24 hours before reaching anyone with authority to act reaches the right person in minutes, with the timeline, exposure amount, and a suggested next step already in the notification.
Why this reduces the need for more headcount
There are three simple mechanisms:
1) Fewer false alarms → less context switching.
A single meaningful incident takes minutes to resolve when the operator can see the relevant timeline, the last 3 logs, business exposure, and a suggested playbook, not ten dashboards. That time saved multiplies across shifts and teams.
2) Prioritized work, not equal-weight tickets.
Humans are terrible at triage when overloaded. A system that ranks incidents by business exposure × probability of escalation makes human judgment focused and effective. You get the benefit of senior judgment without needing more seniors.
3) Automate the 20% low-impact, repeatable fixes.
Many operations problems are repeatable (failed webhook retries, missing metadata, transient vendor timeouts). Automate safe remediations and let the team concentrate on the 20% of work that truly needs human creativity.
Those three effects: less context switching, better prioritization, and safe automation compound quickly. You don’t replace humans; you multiply their impact.
Traditional ops monitoring vs. real-time operational intelligence
- Traditional monitoring treats every system separately. Each tool fires its own alerts, each alert carries a technical severity label, and the ops team receives a flat queue of items marked critical across multiple channels. Finding out which one actually matters requires the team to gather context manually before anyone can act.
- Real-time operational intelligence treats every signal from every system as input into one ranked view. Incidents are scored by business exposure, SLA urgency, and failure probability rather than by what the system log calls critical. The team sees the highest-impact item at the top of one queue, with the context to act already attached.
- On detection speed: Traditional monitoring tells the team when someone opens a dashboard and notices something. Real-time OI tells the team when the threshold is crossed. In a high-transaction operation, those two moments are often 24 to 48 hours apart.
- On context: A traditional alert says "mandate presentation failed, severity: critical." A real-time OI incident card says which bank partner failed, how many transactions are affected, what the value at risk is, how much SLA time remains, and what the playbook is. The difference is not the alert. It is what the person receiving it has to do before they can act.
- On headcount: Traditional monitoring requires more people as signal volume grows, because the bottleneck is human triage time. Real-time OI keeps the prioritisation model, not the team size, doing the triage work.
What good looks like - measurable targets
If you’re trying this for the first time, aim for these rough, realistic wins in 8–12 weeks:
- MTTD cut from hours → minutes for critical flows.
- MTTR reduced by 30–50% for incidents with clear playbooks.
- Alert volume trimmed by 60–80% through better prioritization and de-duplication.
- Manual tickets reduced by X hours/week (measure current weekly person-hours spent on manual fixes and aim to cut it in half).
- Repeat incidents decline as you fix root causes surfaced by prioritized work.
Track these weekly and report real dollars saved by mapping SLA penalties avoided or reclaimed staff hours. Autonmis’ playbooks emphasize this measurement-first approach.
Checkout: How Ops Intelligence Reduces NPAs: Metrics That Matter
A short, practical playbook to get started (4–8 weeks)
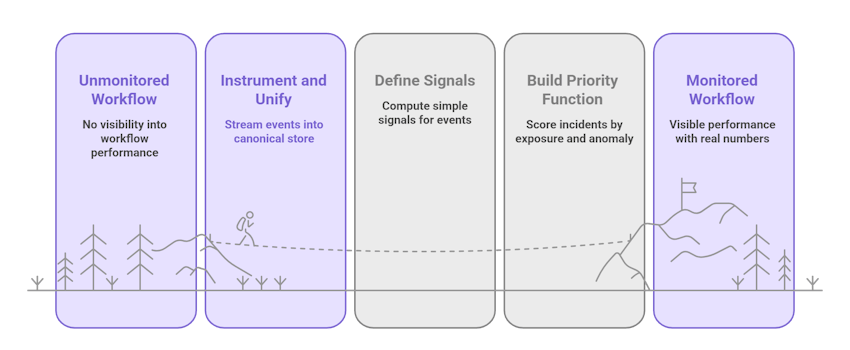
Week 0: pick one high-value workflow.
Choose a workflow with clear business impact: payments, loan disbursements, or reconciliations. Keep it narrow.
Week 1: instrument and unify.
Stream events into a canonical store. Normalize timestamps, transaction IDs, status codes, and business metadata (customer tier, amount, SLA). This step is boring but critical.
Week 2: define signals and exposures.
For each event, compute simple signals: duration, retry_count, missing_fields, vendor_latency, and monetary exposure. Define how exposure maps to your business (e.g., amount × SLA penalty).
Week 3: build a priority function.
Make a rule that scores incidents by exposure × anomaly_score (or simple heuristics to begin). Prioritize what the human sees: top 50 incidents by score.
Week 4: create incident cards and one-click playbooks.
Incident card = timeline + logs + business exposure + suggested playbook. Playbooks should be short (2–4 steps) and include who to loop and when to escalate.
Week 5–8: run human-in-the-loop and iterate.
Let operators validate alerts and improve rules. Remove rules that cause noise. Add small automations for the most common safe fixes.
This narrow pilot makes the problem visible and gives you real numbers to show the value.
Tactical design choices that matter (so you don’t waste time)
- Prioritize business exposure, not volume. Fixing a $1M stalled settlement is better than 100 low-value retries.
- Show evidence first. Every recommendation must include the timeline and the raw signals used to make it. Humans trust evidence, not assertions.
- Use a short human validation window. Tune thresholds with people in the loop for 2–3 weeks before automating.
- Measure cost of manual work. The hidden cost of manual operations is real - calculate person-hours spent on repetitive tasks and use that as conservative ROI.
What to avoid (leaders’ traps)
- Buying more dashboards. Dashboards summarize; they don’t reduce decision work. Actionable queues do.
- Over-automating without telemetry. If automation runs blindly, you risk repeating mistakes at scale. Always log outcomes and provide an undo or human review path.
- Letting ownership be fuzzy. Anything without an owner becomes a recurring gap. Make owners visible and accountable.
- Measuring activity, not outcome. Counting alerts closed isn’t the same as counting customer impact addressed.
Checkout: The Architecture Behind Real-Time Ops Intelligence: RAG + NL2SQL Explained
Final note
Operators, analysts and engineers are your most valuable resource. The real question is whether you’re spending their time on meaningful judgment or on repetitive context gathering. If you remove the friction that makes small decisions slow the back-and-forth, the duplicated lookups, the ownerless alerts you’ll get faster decisions, less customer impact, and, yes, better use of existing headcount.
Frequently Asked Questions
What is real-time operational intelligence and how is it different from a monitoring dashboard?
Real-time operational intelligence converts live operational signals into ranked, actionable decisions and routes them to the right person immediately. A monitoring dashboard displays data to someone who is already looking at a screen. The practical difference: real-time OI comes to you when something needs attention. A dashboard waits for you to come to it. In fast-moving operations, this architectural difference is what separates a 10-minute fix from a 24-hour post-mortem.
How much does detection delay actually cost in BFSI operations?
The cost is not linear. A stuck disbursement caught within one hour takes 10 to 15 minutes to resolve. The same exception discovered 24 hours later involves customer escalation, regulatory documentation, and a post-mortem, a cost multiplier of 15 to 20 times for the same root cause. For mid-market Indian lending operations with high transaction volumes, detection and triage delays are the consistent source of ₹3 to 5 crore in monthly operational leakage, not the exceptions themselves.
Does real-time ops intelligence reduce headcount?
No. It changes what the team works on. Instead of spending the first 20 minutes of every incident gathering context across multiple dashboards and systems, the team receives a pre-contextualised incident card and acts immediately. That time saving multiplies across shifts. The bottleneck in most ops teams is not the number of people. It is the time each person spends gathering context before they can do anything useful.
How long does a pilot take to show measurable results?
A well-scoped pilot on one workflow, loan disbursements, payment monitoring, or reconciliation exceptions, shows measurable results in four to eight weeks. Measurable means MTTR reduced by 30 to 50 percent for incidents with clear playbooks, alert volume actively worked by the team reduced by 60 to 80 percent, and at least one class of exception that previously reached the team as a customer complaint now being caught and resolved internally.
What do you need to get started with real-time operational intelligence?
Three things: a way to stream or batch events from your operational systems into one place, a set of business rules that translate those events into ranked alerts by value at risk and SLA urgency, and a routing layer that sends each alert to a named owner. The playbook in this article covers all three steps. The most time-consuming part is week one, normalising timestamps, transaction IDs, and business metadata across systems, not the alert logic itself.
Recommended Blogs

5/4/2026
Abhranshu
The Data to Decision Gap: What It Costs and Why It Exists

4/16/2026
AB
How to Preserve Institutional Knowledge in Data Workflows
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.