1/15/2026

AB
The Architecture Behind Real-Time Ops Intelligence: RAG + NL2SQL Explained
Explore the architecture behind real-time ops intelligence and how RAG + NL2SQL enhances business ops, enabling proactive problem-solving in data-driven industries.

Too many operations teams in lending, finance, logistics, and other data-intensive industries only find out about problems when someone escalates them; via Slack pings, support tickets, or partner complaints.
A transaction sits in a pending state for hours. A compliance event goes unflagged. A key SLA deadline is missed.
All of this is visible in your operational systems, but most organizations still don’t detect or act on it in time.
The stack that reliably moves from “data knows” to “humans act” must solve three practical things at once: (1) preserve event-level truth; (2) make business meaning executable and discoverable (a semantic layer); and (3) ensure any generated SQL is constrained, auditable and mapped to action. Do those three and RAG + NL2SQL becomes useful in production. Skip them and you get faster but less trustworthy answers.
Below I lay out the practical architecture, the hard trade-offs, and the real industry evidence that these pieces are necessary.
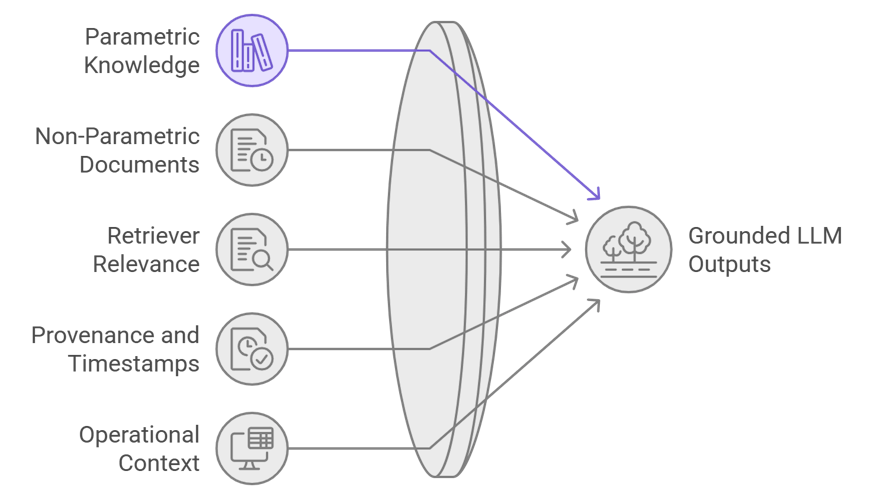
1) RAG isn’t a magic fix, it’s grounding.
Retrieval-Augmented Generation (RAG) was introduced to combine parametric knowledge in LLMs with non-parametric retrieved documents so generated outputs are better grounded in facts. The original RAG work and subsequent reviews show the method reduces hallucination and improves factual accuracy when the retriever gives relevant supporting content. This is why production RAG systems surface provenance and timestamped documents alongside answers.
That matters operationally: if your system can pull the exact metric definition, schema snippet, prior validated query and SLA rule before generating SQL, the output is anchored to your reality, not the model’s general knowledge.
Checkout: What is Operational Intelligence (OI)? Complete 2025 Overview
2) NL2SQL fails in enterprises because the problem is semantic, not purely syntactic
State-of-the-art text-to-SQL research and recent surveys make this explicit: real enterprise deployments must handle multi-database queries, heterogeneous schemas, shifting canonical definitions and the need for interpretability. Academic work (and industry post-mortems) list the practical failure modes: mis-selected databases/tables, incorrect joins, and queries that are syntactically valid but semantically wrong for the business. In short, NL2SQL alone solves syntax; it does not solve semantics.
So the architecture must force NL2SQL to consume canonical, curated definitions (the semantic layer) and recent validated examples before emitting SQL.
3) The semantic layer is now a mainstream best practice
Modern analytics engineering has converged on a simple truth: if you want consistent, trustworthy metrics and queries, define metric logic once in a governed layer. Tools and guidance from the dbt community and others make this explicit: a semantic layer maps business terms to canonical SQL and schema links, and it’s what lets different teams ask the same question and get the same answer. In ops contexts, this layer must encode lifecycle stages, SLA semantics, ownership, and the entity-linking rules across systems.
Practically, that means models like stuck_disbursement_v1 are first-class objects (SQL + time semantics + ownership rules + versioning).
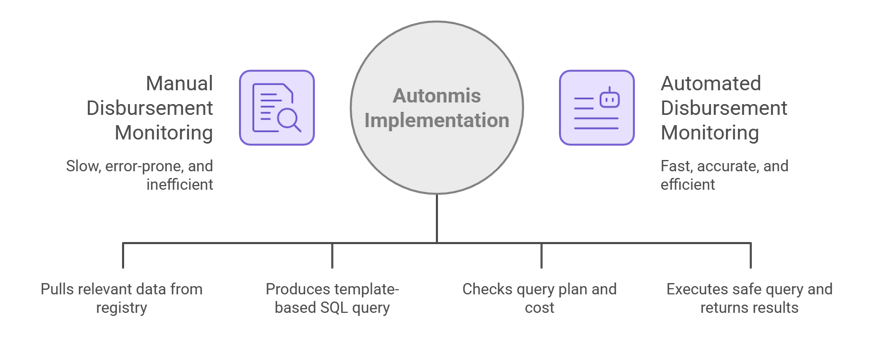
4) A practical, production-grade flow (step-by-step)
Here’s a concise pipeline that enterprise teams actually implement:
- Event Truth (landing zone): CDC or short-interval micro-batches land raw events (with event_id, source_ts, ingest_ts, run_id). Preserve append-only events for replay and explanation. (If you collapse too early you lose the clocks you need for SLAs and for deciding “now”.)
Autonmi Onboarding Document - Staging & curated views: small, frequent refresh staging tables provide performance-safe access for ops queries. These are the only tables the NL2SQL layer can query for ops intents.
- Semantic registry: a governed catalog of definitions (approval_rate, stuck_disbursement_v2) that include SQL/logic, time semantics, owners and priority. Versioned and discoverable by retrieval.
- RAG retrieval + context assembly: when a question arrives, the retriever returns: the semantic registry entry, recent similar queries (gold-standard examples), relevant schema snippets, SLA config rows and recent incident signatures. Retrieval should be hybrid (dense embeddings + lexical) and re-ranked by recency and business impact. Microsoft/Azure guidance and industry practices emphasize grounding prompts with exactly these artifacts.
- Constrained NL2SQL generation: the model maps intent → template + params (rather than free-form SQL), using only whitelisted staging views. Pre-execution checks (explain plan, row-count estimate, banned joins) prevent expensive or risky executions. Audit logs capture the generated SQL and provenance.
- Action object outputs: results do not stop at a table. They become tracked objects: queued exceptions, SLA timers, assigned owners, and an audit trail that links back to the registry definition and the SQL that ran.
- Learning loop: resolved incidents are normalized into signatures and, under governance, promoted into the registry as suggested canonical fixes.
This is not theoretical, it’s the pattern adopted by modern operational intelligence and analytics engineering pipelines.

Checkout: RAG for NL2SQL: Beyond Basics for Enterprise Database Accuracy
5) Trade-offs you must accept
- Governance over convenience. If you want correctness, you must constrain freedom: curated staging, template-only NL2SQL for ops, versioned metric promotion. That irritates analysts initially, but it is how predictable ops is achieved.
- Storage and engineering complexity. Keep event truth and provenance; it costs storage and discipline. Replay ability and explain-ability justify that cost.
- Retrieval tuning. RAG is only as good as retrieval. Invest in embedding quality, metadata, reranking heuristics and TTLs for docs.
- Execution safety. Validate queries, sandbox heavy runs, and provide role-based overrides for exploratory analysts.
6) What the industry shows works (examples & sources)
- The original RAG design and empirical results show dramatic improvements in factual grounding when retrieval is used prior to generation. This foundational research is the reason production RAG systems persist.
- Enterprise guidance from cloud vendors and analytics platforms emphasizes grounding and provenance for retrieval workflows - not least because production systems must be auditable and updatable in real time. Microsoft’s RAG docs and Azure guidance reflect this approach.
- Data/analytics tooling communities (dbt, ThoughtSpot, Datafold) advocate centralized metric definitions and semantic layers as the single source of truth, the practical scaffolding required for trustworthy NL2SQL in enterprises.
7) What this looks like for a lender (practical example)
Imagine a user asks: “Show disbursements stuck >60m by bank with SLA breach.”
- Retriever pulls stuck_disbursement_v2 from the registry (authoritative definition), the staging view schema stg_disbursements, recent validated example queries, and SLA config table.
- Generator produces a template-based SQL that only touches stg_* views.
- The query is dry-run to check plan/cost. If safe, it executes. Results appear as a queue object with owner_id, sla_timer, provenance (registry id + query id), and a recommended playbook link. That object can be assigned, messaged to Slack, or trigger an automated retry if permitted.
This flow is consistent with Autonmis’ product framing; live command center, alert trackers, and AI-assisted notebooks, but built in a way that enforces operational truth rather than relying on the model to guess semantics.
Checkout: How to Implement RAG in Business Operations: Step-by-Step Guide
Bottom line
RAG + NL2SQL will work in production only when it is treated as a piece of a disciplined architecture: event truth + semantic layer + retrieval + constrained generation + action outputs + learning loop. The research base (RAG), the analytics engineering best practices (semantic layers), and production experience (query validation, governance) all point in the same direction: constrain the model with your business reality, or it will confidently produce the wrong answers.
The takeaway
This architecture is hard to build correctly, which is why most teams don’t.
Autonmis exists to make it real, on top of your current systems, without months of custom engineering.
From blind → real-time. From reactive → controlled.
If earlier visibility, fewer blind spots, and predictable operations matter, the next step isn’t another dashboard. It’s seeing this pattern run on your own data.
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.