Table of Contents
How a COO Uses Autonmis for Predictable Operations
Invalid Date

AB

Operations has always been the function that carries the weight of the business. Revenue might be a function of sales and product, but profitability is a function of operational discipline. The last five years have made this brutally clear: customer expectations have hardened, regulatory scrutiny has increased, and workflows are now distributed across dozens of systems that weren’t designed to talk to each other.
The result is universal:
Operations today fails silently. And it fails long before leadership discovers it.
For COOs, the real challenge is no longer “What went wrong?” , it is “How fast do we know, and how fast can we course-correct?”
The core idea
Autonmis doesn’t replace systems. It reduces the time between a thing breaking and a human who can fix it getting the right context, ownership, and next steps. Reduce that clock and you reduce customer pain, audit risk, and firefighting.
Three clocks you must own:
- Discovery time: when a failure happens → someone knows.
- Assignment time: when someone is named to fix it.
- Resolution time (TTR): when it’s actually fixed and verified.
Shorten discovery first. The rest follows.
What Autonmis looks like to a COO (not technically, practically)
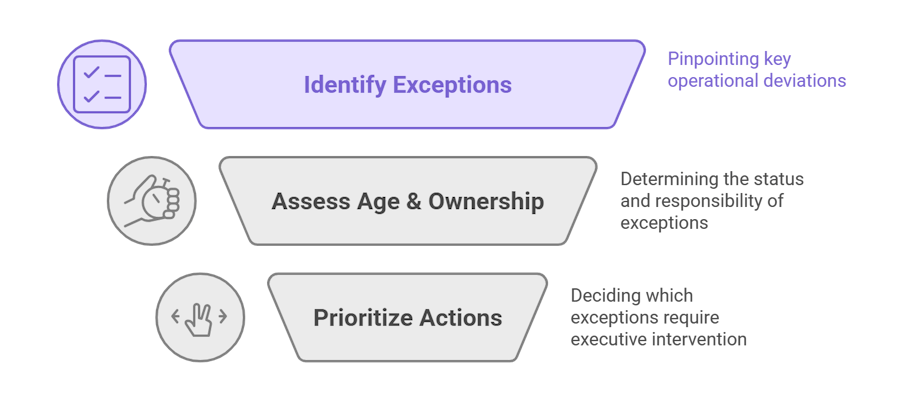
Think of Autonmis as your executive inbox for operational truth. On any morning you should be able to open one view and answer three questions quickly:
- What high-impact exceptions appeared in the last 24 hours?
- Which of those are aged, unowned, or recurring?
- Which ones require my muscle (reorg, budget, vendor change) vs. which are tactical and should be delegated?
You don’t open Autonmis to “see logs.” You open it to see the state of the business - the things that, if left, will become strategic problems in 30–90 days.
Checkout: The Future of Business Operations: From Firefighting to AI-Driven Flow
Daily: the 15–30 minute leadership ritual
This is the heartbeat. The daily routine is brief, focused, and decision-driven.
What you review (15–30 minutes):
- Top 5 exceptions (by estimated impact): items Autonmis ranks using business impact, customer sensitivity, and age.
- Discovery time trend: did average discovery time move up or down vs. yesterday?
- Aged queue snapshot: items older than SLA with owners and root-cause tags.
- Vendor alerts: correlated vendor failures affecting customers or throughput.
- “What changed” card: a plain-English summary of the single biggest variance driver since yesterday.
Decisions you make:
- Escalate: If the incident is cross-functional, aged, or high impact, you open an immediate cross-team incident with a 2-hour executive checkpoint.
- Reallocate: If the queue shows a team consistently overloaded, you shift headcount or reprioritize work.
- Greenlight an interim fix: If a workaround reduces customer impact, approve it and mandate a postmortem.
- Defer & delegate: For tactical exceptions, confirm owner + SLA and let the ops lead run the queue.
Why this matters: daily discipline keeps discovery times low, prevents small problems from compounding, and turns firefighting into predictable workload.
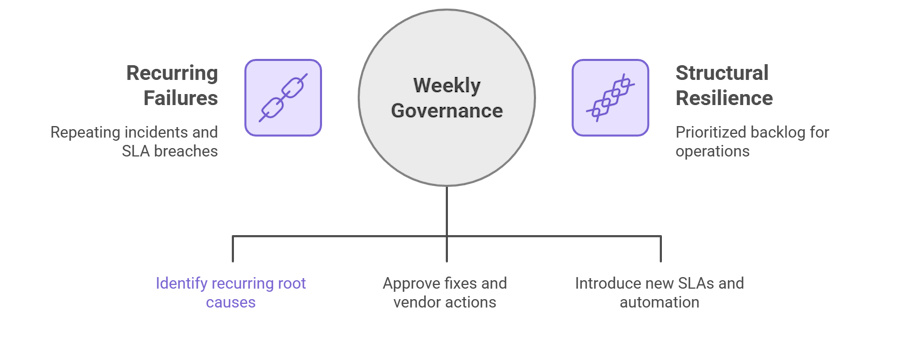
Weekly: governance that actually reduces repeat failures
Weekly is where you turn patterns into policy.
What you review (60–90 minutes):
- Recurring root causes: Autonmis groups exceptions into recurring patterns (same failure class hitting multiple records).
- SLA compliance & aging heatmap: which flows are repeatedly breaching SLAs and why.
- Vendor scorecards: incidents, MTTR, and trend for each vendor.
- Process debt queue: repeated exceptions that require design changes rather than tactical fixes.
- Improvement backlog: proposals (engineering, process, vendor, product) with estimated impact and cost.
Decisions you make:
- Structural fixes: approve a cross-functional sprint for the highest-value process debt item.
- Vendor actions: escalate to procurement or switch vendors when scorecards show systematic failures.
- Governance changes: introduce new SLAs, change owner mappings, or tighten escalation ladders.
- Resource investments: fund automation where repeat manual fixes consume disproportionate time.
Why this matters: weekly governance converts incident noise into a prioritized product backlog for operations, the difference between repeating failures and structural resilience.
Checkout: The Cost of Escalation Delays in Lending Ops
Monthly / Quarterly: the strategic cycle
This is where the COO’s foresight and the board’s expectations align.
What you review:
- Trend narrative: discovery time, assignment time, TTR, unresolved backlog, and their trajectory.
- Business impact ledger: estimated customer impact and financial exposure from operational failures.
- Capabilities gaps: what tooling, headcount, or vendor upgrades are required to sustain improvements.
- Compliance posture: audit-ready evidence for any recurring exception categories that touch regulation or finance.
Decisions you make:
- Raise or reallocate budget: invest in automation, retries, or data contracts where ROI is clear.
- Reorganize ownership: move responsibilities between teams to remove single points of failure.
- Set leadership KPIs: tie discovery time and % of aged exceptions to leadership reviews and OKRs.
- Approve cross-org programs: product/engineering/ops initiatives that remove systemic causes.
Why this matters: monthly and quarterly rhythm institutionalizes predictability - the COO’s role shifts from reactive firefighter to strategic architect.
How each common use-case becomes a COO decision
Below are condensed examples showing how Autonmis surfaces problems and what a COO actually does with that visibility.
- Stuck handoffs: Autonmis shows a rising cluster of “approved → not fulfilled” across a region. COO asks: is this code, vendor, or process? If vendor, instruct procurement to open SLA negotiation; if code, greenlight a hotfix and mandate a postmortem.
- Activation drop-offs: A spike in “missing callback” for a key funnel segment appears. COO orders a prioritized experiment: triage 5% of cases manually for 7 days, measure uplift, then fund the automation if conversion improves.
- Incident duplication: Incidents are repeatedly involving multiple teams. COO mandates deterministic ownership rules (mapping by event type/product line) and ties adherence to weekly reviews.
- Vendor cascade: Correlated vendor failures affect high-value customers. COO triggers fallback flows immediately for VIPs and schedules an emergency vendor review with procurement & legal.
- Reconciliation mismatches: Daily unreconciled counts are trending up. COO approves a dedicated reconciliation sprint and requires daily checkpoint reporting until counts normalize.
- Leadership MIS variance: Autonmis shows that a small set of recurring exceptions caused a 7% drop in throughput; COO presents this to the exec team with a 30/60/90 plan to fix the top causes.
Those are the real-world moves, not “setup” tasks but decisions that change outcomes.
Checkout: How GFF 2025 Changes the Way BFSI Will Operate in India
A practical 30-day pilot for a COO (what to run and why)
Week 0 (Prep): pick 2–3 high-impact flows (handoff, activation, reconciliation). Assign an ops lead and give read-only access to minimal event sources.
Days 1–5: map the event sequences, agree detection rules (missing event, latency threshold, error clusters).
Days 6–12: turn rules into queues with deterministic owners and short playbooks. Route notifications to existing channels.
Days 13–20: operate daily, log SLA breaches, capture examples of recurring failures.
Days 21–30: run weekly governance review, present first “what changed” leadership pack, and decide the first structural fix. Measure: discovery time, assignment time, TTR, and % aged exceptions.
Expected outcome: visible reductions in discovery time and a leadership-ready MIS at day 30.
Governance rules that preserve trust
- Deterministic owner mapping - by product line, region, or event type. No ambiguity.
- SLA ladder - acknowledge and resolve windows by severity; auto-escalate on breach.
- Audit trail - immutable timestamps and reason codes for detection → assignment → closure.
- Lean playbooks - 2–3 step remediations that teams can execute under pressure.
These are non-negotiable. They turn visibility into accountability.
How you prove success to the board
Measure the clocks and their business impact:
- Discovery time (median & 95th percentile) - down to minutes for priority flows.
- Assignment time - near-instant for triageable exceptions.
- TTR - 30–60% reduction on piloted flows.
- Business impact estimate - reduced customer refunds, fewer SLA breaches, less month-end toil.
Report these as a narrative: what we fixed, why it mattered, and what we’ll fix next.
Final note
“How a COO actually uses Autonmis” is not about clicking around a product. It’s about changing how leadership thinks about operations: from chasing incidents to managing clocks and decisions. Autonmis is the command layer that shows you the right problems; your job is to turn those signals into governance, resource decisions, and permanent fixes. Do that, and operations stops being a cost and becomes a compounding advantage.
Recommended Blogs

5/4/2026
Abhranshu
The Data to Decision Gap: What It Costs and Why It Exists

4/16/2026
AB
How to Preserve Institutional Knowledge in Data Workflows
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.