3/18/2025

AB
What Is the Modern Data Stack and How Does It Work in 2025?
The Modern Data Stack (MDS) is a collection of cloud-native, best-of-breed tools integrated to efficiently move, store, transform, analyze, and activate data. It enables businesses to gain rapid insights and operationalize data for competitive advantage through a flexible and scalable architecture.

For years, data initiatives promised transformation but often delivered complexity and frustration. You've likely experienced the pain: data locked in silos, creaking legacy systems struggling with new data types, insights arriving too late to be actionable, and a constant battle to ensure data quality and reliability. Business teams demand more, faster, while data teams are stretched thin.
If this sounds familiar, you're not alone. These aren't just operational headaches; they're significant roadblocks to innovation, efficiency, and competitive advantage.
The good news? A fundamental shift in data architecture, known as the Modern Data Stack (MDS), directly tackles these long-standing industry pain points. It’s not just a new set of tools, but a new philosophy for building agile, scalable, and user-centric data platforms.
What is the Modern Data Stack, Really? (And Why It’s Not Just Hype)
The Modern Data Stack is an ecosystem of primarily cloud-native, best-of-breed tools designed for the end-to-end journey of your data. Its power lies in addressing specific historical limitations:
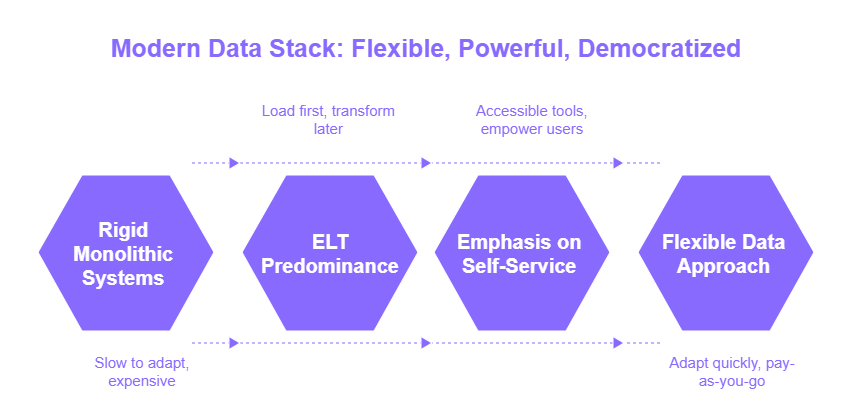
- Pain Point: Rigid, monolithic systems that are slow to adapt and expensive to scale.
- MDS Solution: Modularity and Cloud-Nativity. Think of interchangeable components you select for specific tasks (ingestion, storage, transformation, etc.), all leveraging the cloud's inherent scalability and pay-as-you-go cost models. This means you can adapt quickly without overhauling your entire system or overprovisioning resources.
- Pain Point: Brittle ETL (Extract, Transform, Load) processes that break easily and require significant upfront modeling, limiting access to raw data for exploration.
- MDS Solution: ELT (Extract, Load, Transform) Predominance. Raw data is loaded into a powerful cloud data warehouse or lakehouse first. Transformations happen later, within the warehouse, using its processing power. This offers greater flexibility, access to raw data for advanced analytics, and often simplifies the initial ingestion pipelines.
- Pain Point: Data access and analysis bottlenecked by specialized teams, leading to slow decision-making.
- MDS Solution: Emphasis on Self-Service. Tools are designed to be more accessible, empowering analysts and even less technical users to explore data and generate insights independently.
In essence, the MDS moves away from the clunky, on-premise data infrastructures of the past towards a more flexible, powerful, and democratized approach.
Checkout: What Is Univariate Analysis? How to Use It in Data Exploration
How the Modern Data Stack Delivers: A Component-by-Component Breakdown
Understanding how the MDS solves specific problems requires looking at its key components:
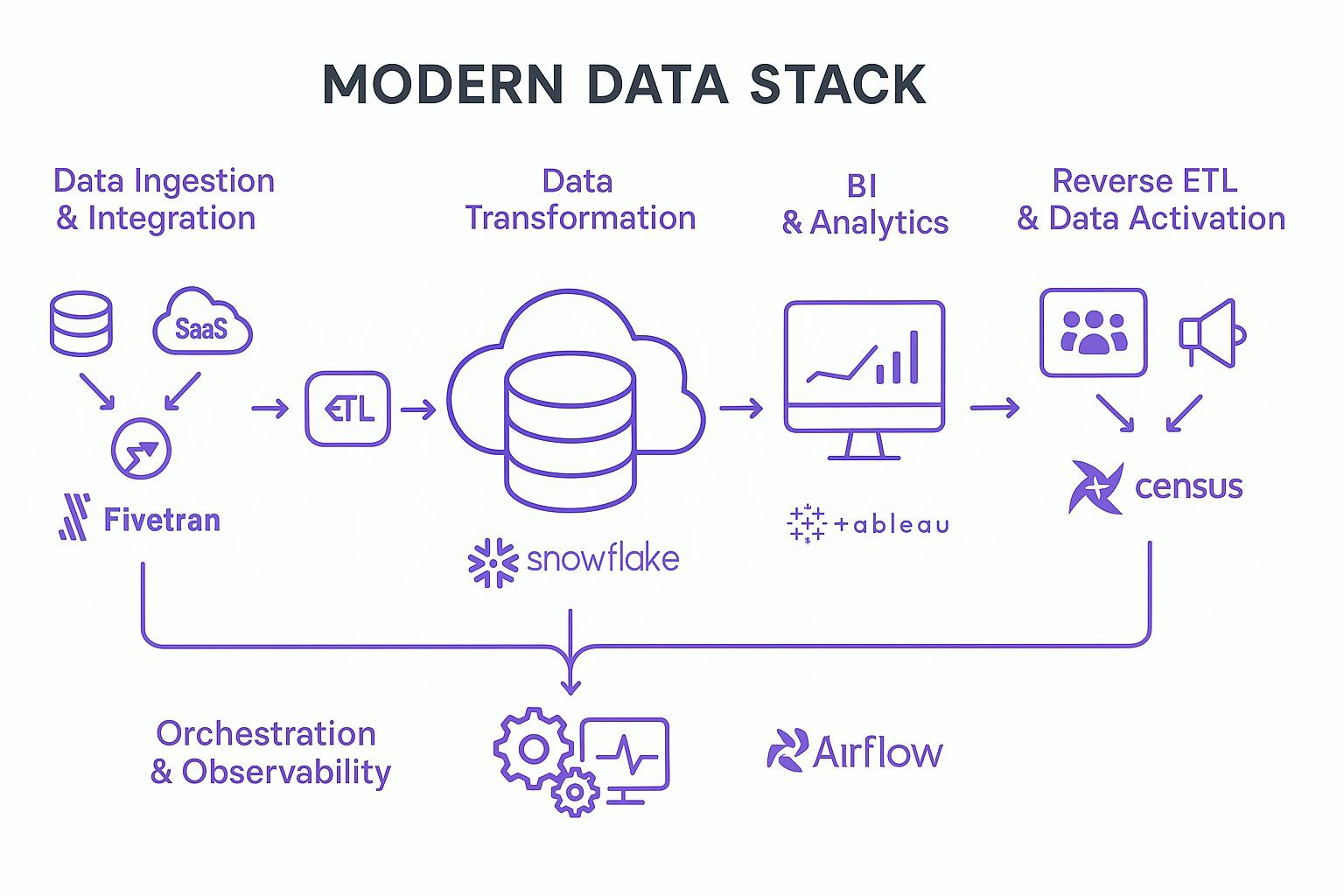
- Data Ingestion & Integration:
- The Pain: Pulling data from diverse, often siloed sources (databases, SaaS apps, APIs) is time-consuming, error-prone, and requires constant custom scripting.
- The MDS Fix: Tools like Fivetran, Airbyte, or Stitch automate data extraction and loading. With pre-built connectors for hundreds of sources, they drastically reduce engineering overhead and ensure consistent data flow into your central repository. This is the "E" and "L" of ELT, done efficiently.
- Storage & Warehousing (The Core):
- The Pain: Traditional on-premise data warehouses are expensive to maintain, struggle with modern data volumes and variety, and couple storage with compute, leading to inefficiencies.
- The MDS Fix: Cloud Data Warehouses (CDWs) like Snowflake, Google BigQuery, Amazon Redshift, and Azure Synapse Analytics, or Data Lakehouses like Databricks. These platforms offer:
- Decoupled Storage and Compute: Scale and pay for them independently.
- Elasticity: Handle massive data volumes and fluctuating workloads.
- Support for Diverse Data: Store and process structured, semi-structured, and even unstructured data. This layer is where raw data lands and becomes available for transformation and analysis.
- Data Transformation:
- The Pain: Transformation logic buried in complex, hard-to-maintain scripts or proprietary ETL tools, leading to "black box" processes, data quality issues, and difficulty in making changes.
- The MDS Fix: Tools like dbt (data build tool) have been a game-changer. dbt enables data teams to transform data inside the data warehouse using SQL—a language many already know. It brings software engineering best practices (version control, testing, documentation) to the analytics workflow.
- This transparency and structure lead to more reliable, auditable, and maintainable data models.
- Business Intelligence (BI) & Analytics:
- The Pain: Business users waiting days or weeks for reports; analysts struggling with outdated or inflexible BI tools; data scientists working in isolation.
- The MDS Fix: Modern BI platforms (Tableau, Power BI, Looker, ThoughtSpot, Metabase) and data science environments (Hex, Jupyter notebooks integrated with the warehouse) connect directly to your CDW or lakehouse. They offer intuitive interfaces for exploration, visualization, and advanced analysis, fostering self-service and speeding up the time to insight.
- Reverse ETL & Data Activation:
- The Pain: Valuable insights and enriched data (e.g., customer lifetime value, product usage segments) remain locked within the data warehouse, failing to drive action in frontline business systems.
- The MDS Fix: Reverse ETL tools (Census, Hightouch) operationalize your data. They pipe curated data from the warehouse back into operational tools - CRMs (like Salesforce), marketing automation platforms (like HubSpot), ad platforms, and customer support tools—enabling personalized experiences and data-informed actions at scale.
- Orchestration & Observability (The Unsung Heroes):
- The Pain: Data pipelines failing silently; data quality issues going undetected until they impact business decisions; difficulty managing complex dependencies between data jobs.
- The MDS Fix:
- Orchestration tools (Apache Airflow, Prefect, Dagster) automate, schedule, and monitor data workflows, ensuring jobs run in the correct order and handling failures gracefully.
Data Observability platforms (Monte Carlo, Datadog, Sifflet) provide visibility into data health, alerting teams to issues like schema changes, data freshness problems, or anomalies before they impact downstream consumers. This builds trust in your data.
Fact: According to an IDC report, organizations that effectively leverage their data can see significantly higher revenue growth and operational efficiencies. The MDS is a key enabler for this.
Checkout: What is ELT? Understanding Modern Data Transformation
The Real-World Impact: Why This Matters for Your Organization
Adopting an MDS isn't just about new tech; it's about solving critical business challenges and unlocking opportunities:
- Solve Data Silos & Slow Insights: Get faster, unified access to all your data, dramatically reducing the time it takes to answer critical business questions.
- Boost Agility: Respond rapidly to new market conditions or business requirements by easily integrating new data sources or modifying existing pipelines.
- Enhance Data Reliability & Trust: Improve data quality and consistency through better transformation practices and observability, leading to more confident decision-making.
- Optimize Costs: Pay only for the cloud resources you consume, often leading to lower TCO compared to legacy systems, especially when considering maintenance and upgrade costs.
- Empower Your Teams: Shift from IT-bottlenecked reporting to a culture of self-service analytics, freeing up data engineers to focus on higher-value tasks.
- Build a Foundation for AI/ML: Clean, well-structured, and accessible data in an MDS is the launchpad for impactful artificial intelligence and machine learning initiatives. This is where platforms focused on operationalizing AI on your data, like autonmis.com, can truly accelerate value.
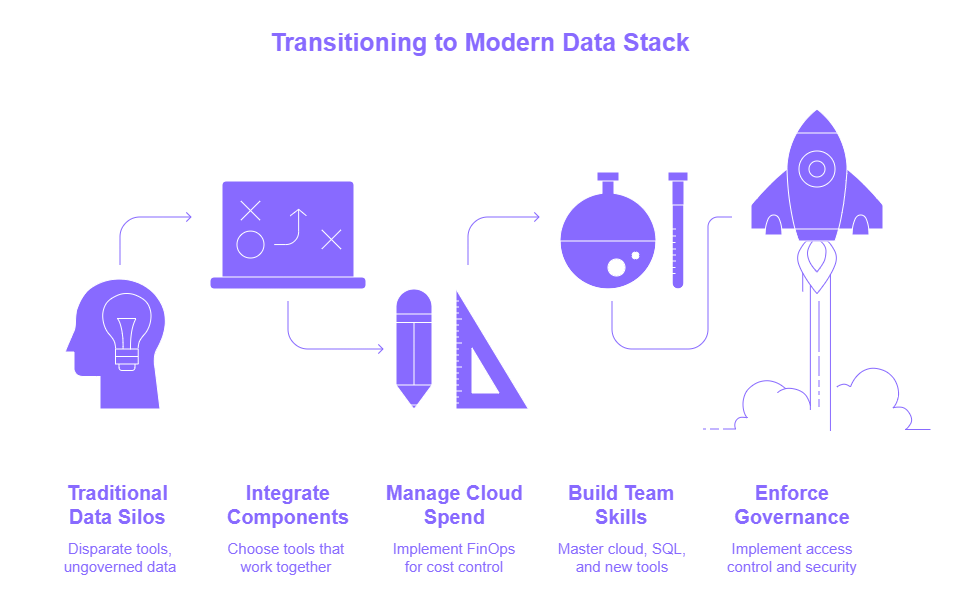
Navigating the Transition: Key Considerations
While adopting an MDS unlocks agility and scale, you’ll need to:
- Avoid Tool Sprawl: Pick components that integrate seamlessly and solve real problems.
- Manage Cloud Spend: Apply FinOps practices to keep usage—and bills—in check.
- Build Skills: Ensure your team masters cloud platforms, SQL (dbt), and any new tools you introduce.
- Enforce Governance: Implement modern access controls, lineage, and security policies across your distributed data estate.
Platforms like Autonmis naturally address these areas in one conversational workspace: its chat-based interface replaces multiple schedulers (simplified orchestration), consolidates costs under a single subscription, uses plain-English commands to onboard analysts quickly, and delivers automatic lineage tracking with real-time alerts - so you gain reliable, governed pipelines without stitching together a dozen point solutions.
Checkout: Understanding Stationarity in Time Series Data: Why It Matters
Is the Modern Data Stack Your Next Strategic Move?
If your current data infrastructure is a source of frustration rather than a catalyst for growth, the answer is likely yes. The MDS is particularly compelling if you aim to:
- Break down data silos and accelerate insight generation.
- Reduce reliance on outdated, inflexible legacy systems.
- Empower business users with self-service capabilities.
- Scale your data operations cost-effectively.
- Lay a robust groundwork for advanced analytics and AI.
The Modern Data Stack offers a clear path away from common data pain points towards a more agile, insightful, and data-driven future. By understanding its core principles and how its components address specific challenges, you can make informed decisions to architect an infrastructure that truly serves your business needs.
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.