7/1/2025

AB
Data Pipeline Architecture Explained: Best Practices 2025
Modern data pipeline architecture isn’t about fancy tools - it’s about building systems that are reliable, observable, and safe to re-run. This guide breaks down 5 essential pillars, shows what top teams are quietly doing, and explains why boring, predictable pipelines are the real goal in 2025.

If you’ve spent enough time working on data systems, you know this already:
Most pipeline issues don’t show up in the code. They show up when someone opens a dashboard and says,
“Hey… this number doesn’t look right.”
That’s the moment every broken contract, half-documented schema, and invisible failure comes due.
And that’s why data pipeline architecture matters - not in theory, but in practice.
This post isn’t about naming layers or redrawing boxes. It’s about how real teams keep pipelines from quietly drifting out of sync.
It’s about what still works when your sources change weekly, your dependencies keep growing, and your business needs answers that don’t come with surprises.
What is a Data Pipeline Architecture, Really?
Forget the textbook definitions. A pipeline architecture is not just a diagram. It’s your interface with reality:
- It’s how customer events land in your warehouse.
- It’s how fraud features get built on time.
- It’s how stale dashboards stop costing you credibility.
At its core, your data pipeline architecture is a combination of workflow logic, tooling choices, contract enforcement, and failure-handling defaults.
If it works, no one notices.
If it breaks, you’ll know by noon - when marketing tells you the monthly active user count dropped to 3.
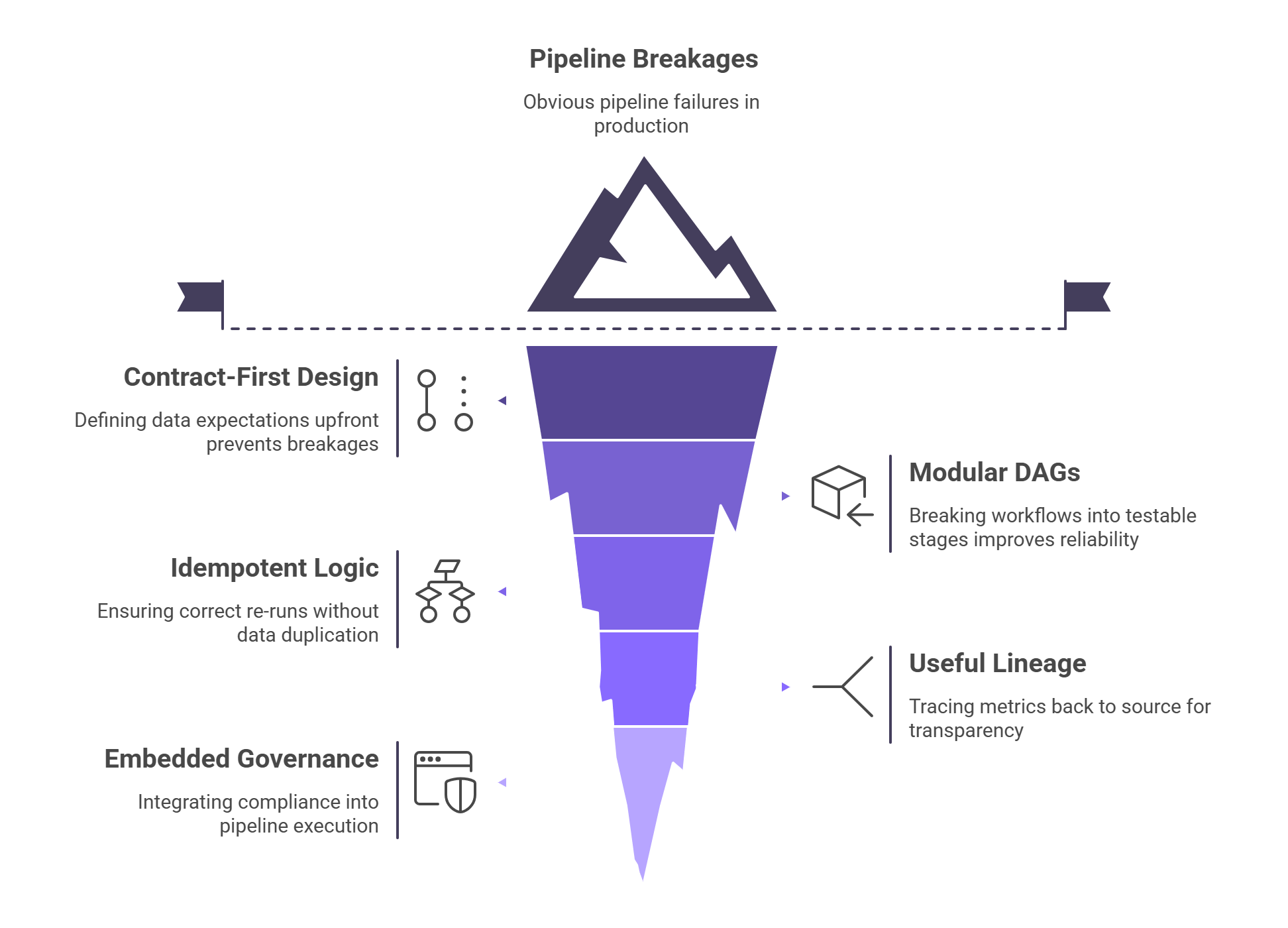
The Five Architectural Anchors of Healthy Pipelines in 2025
Let’s not overcomplicate this. Building pipelines that last doesn’t require 50 tools, just five core practices done with intent:
- 1. Contract-First Design
Define your data expectations up front. Schemas, types, null behavior - all versioned and enforced before ingestion starts. This stops 90% of silent breakages before they ever hit production. - 2. Modular and Observable DAGs
Break your workflows into clean, testable stages. Each step should be easy to retry, emit useful metrics, and stand alone in local dev. No more 22-task DAGs that fail in step 17 with no clues. - 3. Idempotent and Resilient Logic
Your pipeline should be able to re-run yesterday’s data without duplicating rows, skewing metrics, or requiring manual cleanup. Resilience isn't just about retries, it's about correctness on retries. - 4. Lineage That’s Actually Useful
You need to trace a metric all the way back to its source field and know what transformations touched it. Column-level lineage, semantic tags, and change history aren’t extras anymore; they’re survival tools. - 5. Governance That’s Embedded, Not Grafted On
Don’t bolt compliance on after the fact. Data residency rules, encryption policies, and access controls should be part of how the DAG runs, not just paperwork for audits.
Let’s Go Deeper: What the Best Teams Are Quietly Doing
1. Contract-First Isn’t Optional Anymore
The fastest way to break your pipeline is to have an upstream team rename email_address to email in production.
What top teams do differently:
- Define Avro or Protobuf schemas per topic or table.
- Store them in Git.
- CI enforces compatibility before merging code.
- Test data is schema-validated in pre-prod - not “eventually noticed” on Looker.
Quiet trick: Use a .latest alias to avoid hardcoding schema versions downstream, while still keeping versioning explicit.
2. Modular DAGs + Observability = Sanity
If your Airflow DAG has 22 tasks in one linear chain, you’ve already lost.
Modular DAGs (with observable edges and retry logic per node) mean:
- Your enrichment job can fail without taking out your deduplication job.
- You can replay only what’s broken.
- Each module emits metrics: run_time, row_count, null_rate, error_rate.
What the 1% do: Emit semantic context per log line - not just “Job failed,” but “transformation ‘standardize_phone_number’ dropped 34% of rows due to format mismatch.”
3. Idempotency and Reprocessing Logic
Here’s the real test of your architecture: Can you re-run the last 3 days of ingestion without double-counting?
Things that help:
- Deduplicate on (source_id, ingestion_time)
- Use upserts with surrogate keys
- Make batch jobs restartable from checkpoints
Bonus tip: Don’t rely only on primary key deduplication. Add lightweight hash checksums on payload to detect partial duplicates.
4. Lineage That Isn’t Just a Pretty Graph
Real lineage tells you:
- Where a field came from
- What transformations were applied
- What broke last time it changed
Use tools like OpenLineage, DataHub, or Marquez only if you configure them properly. Otherwise, they become unreadable spaghetti charts.
Underrated move: Annotate your lineage with business meaning. That user_id in table A isn’t the same as user_id in table B unless you've verified cardinality and join logic.
5. Governance That Ships with the Pipeline
If your governance team is a Slack thread, you're playing with fire.
In 2025, smart teams embed governance rules into their pipelines:
- Row-level access filters baked into queries
- Geo-aware storage routing (e.g., UAE vs. EU partition buckets)
- Encrypting PII fields in-place with keys managed by region
Clever implementation: Store data_classification_level as metadata alongside each table. Then use it to auto-enforce masking or redaction policies at query time.
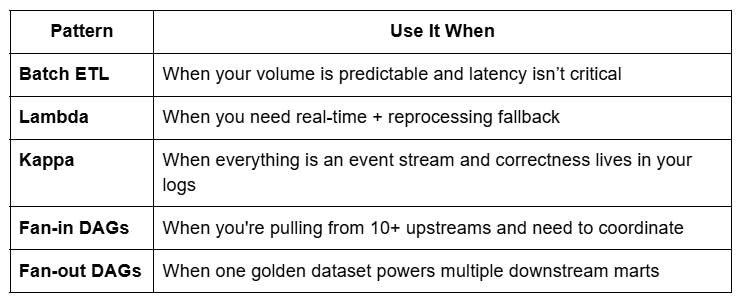
Patterns That Hold Up (and When to Use Them)
The Stuff Almost No One Talks About
Schema Contract CI Saves Hours
Use Buf or Avro tools to enforce schema compatibility as part of your CI. Add a fail-fast job in your GitHub Actions that blocks breaking changes before they go live.
Semantic Drift Is Your Real Enemy
If customer_age starts spiking but the column is technically valid (not null, not broken), no alert fires. But it’s broken. Use semantic anomaly detection, monitor metrics like min/max/stddev per column daily.
Very few teams do this. It’s your early warning system before a model silently degrades.
Airflow Isn’t Enough
Airflow will retry your failed job. It won’t fix your corrupted inputs. Invest in data contracts + monitoring, not just orchestration.
Wrapping It Up: The Point Is to Be Boring
Strong pipelines don’t win awards.
They just don’t wake you up at night.
Build with:
- Schemas that fail loudly in staging
- Logs that explain, not confuse
- Lineage that traces backwards when business asks, “Why does this number look wrong?”
And above all: optimize for clarity, not cleverness.
Because in this world, simple is reliable.
And reliable scales.
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.