7/8/2025

AB
How to Implement RAG in Business Operations: Step-by-Step Guide
Discover how to implement RAG in business operations. Simplify data access and enhance decision-making with practical, easy-to-follow steps.

When teams talk about AI, it often feels like you need a PhD or a fancy R&D budget to get anything going. But Retrieval‑Augmented Generation (RAG) doesn’t have to be a moonshot. It’s really just a way to let your AI tool peek into your own documents before answering questions. Here’s how to bring RAG in Business Operations into your day‑to‑day work - step by step, with words you’d use in a team chat.
Why RAG Matters
You’ve probably heard that AI can “transform” everything. That sounds great, but in most teams, the real hurdles are:
- Data scattered everywhere: Spreadsheets in one place, docs in another, Slack threads in a third.
- Slow answers: Waiting days for someone to dig up a policy, a report, or a past decision.
- Mistrust of “the bot”: If an AI assistant gives a wrong answer, people lose faith fast.
Retrieval‑Augmented Generation (RAG) doesn’t fix every problem overnight - but it can make it easier for teams to get grounded answers, without hallucinations and without hunting through ten systems.
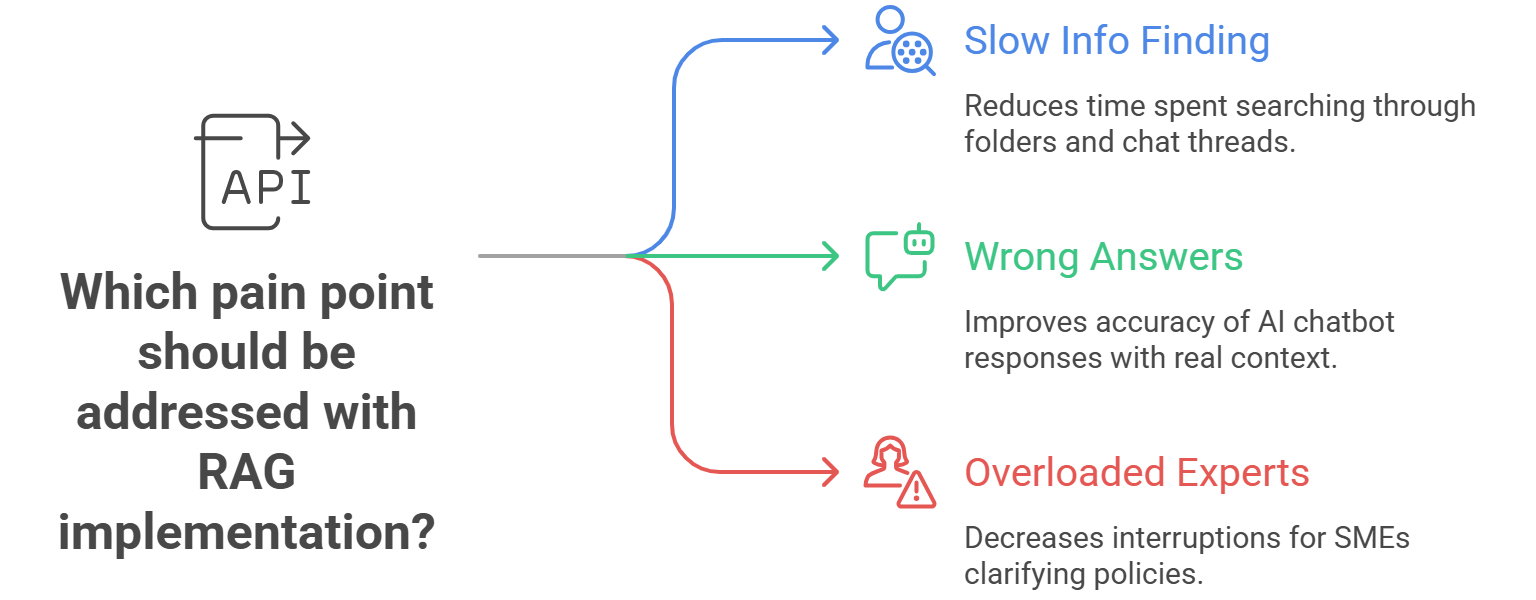
1. Nail the Problem First
Before you write a single line of code or spin up a database, be crystal clear about what you want to fix:
- Slow info finding: People spend hours hunting through folders and chat threads.
- Wrong answers: Generic AI chatbots guess without real context.
- Overloaded experts: SMEs get pings all day to clarify policies or past decisions.
Pick one pain point. Maybe it’s “Get HR policy answers in under a minute,” or “Help account managers pull past proposals.” Keep it tight and focused on Implementing RAG in Business Operations for that specific need.
Checkout: Data Pipeline Architecture Explained: Best Practices 2025
2. Gather and Clean Your Source Material
You need a single place (or two) where most of your key documents live:
1. List your essentials
Policies, playbooks, onboarding guides
Customer proposals, SLA docs, product spec sheets
2. Export to text
Convert PDFs, Word files, Confluence pages to plain text or Markdown
3. Clean up
Remove duplicates, outdated docs, random meeting notes
Tip: Treat this like spring cleaning. If you wouldn’t trust the file to answer a question, ditch it before you ingest it.
3. Split Text into Bite‑Sized Chunks
Rather than feed a giant 20‑page manual to an AI model all at once, break it down:
- Size matters: Aim for chunks of 150–300 words.
- Overlap a bit: Let each chunk share 10–20% of its text with the next. This keeps ideas from getting chopped awkwardly.
- Label each chunk: Note where it came from (e.g., “HR‑Benefits‑Page1,” “Proposal‑Template‑SectionB”).
Why it matters: Proper chunking equals better, more focused answers. Bad chunks give you garbage responses.
4. Turn Text into Numbers (Embeddings)
AI models work with vectors - lists of numbers that capture the gist of a sentence or paragraph.
- Pick an embedding model
- OpenAI’s embeddings (easy, reliable) or an open‑source model on Hugging Face.
- Embed every chunk
- Send each chunk through the model; stash the resulting vector alongside its label.
No need to reinvent the wheel: these embedding services come ready to go.
5. Store Vectors in a Fast, Purpose‑Built Database
A regular database won’t cut it when you need “find the closest vector” in milliseconds. Look at:
Pinecone: Fully managed, easy to scale. Paid service.
Weaviate: Open‑source, hybrid search. Need to host/manage yourself.
Milvus: Great for large clusters. More setup work.
Qdrant: Lightweight, built‑in filters. Smaller community
Pick one that fits your budget and team skills. If you already run Kubernetes, Milvus can slide right in. If you’d rather click‑and‑go, Pinecone works.
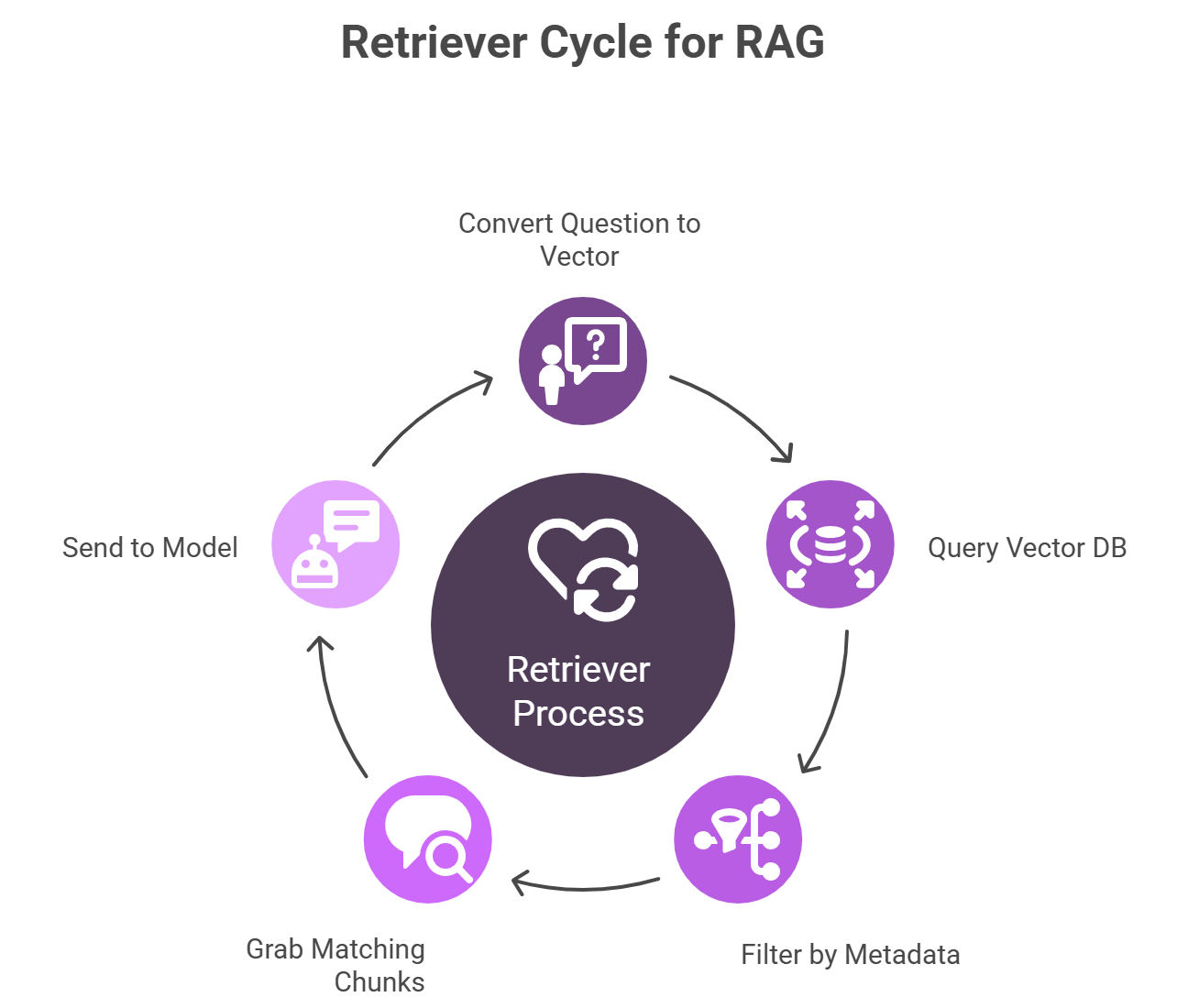
6. Build a Simple Retriever
Your retriever is the code that, given a user question, finds the top 3–5 most relevant chunks:
- Convert question to a vector (same embedding model).
- Query your vector DB for nearest neighbors.
- Optionally filter by metadata (e.g., department = “Sales”).
- Grab the matching chunks and send them on to the model.
A quick Python pseudocode:
This simple retriever is the heart of Business Operations with RAG, making sure only the most relevant info reaches your AI.
Checkout: How AI is Transforming the Role of Data Engineer
7. Prompt the LLM with Care
Don’t overload the model with every chunk in your company. Give it just what it needs:
Keep the system message short. People skip walls of text.
8. Keep an Eye on Governance and Feedback
People trust tools they can correct. Build in a thumbs‑up/thumbs‑down on every answer.
- Log everything: Store question, chunks used, answer, and user rating.
- Review weekly: Spot repeat misses and fix chunking or prompts.
- Prune old content: If nobody uses a doc, it might be stale - archive or delete it.
Trust grows when mistakes get fixed fast.
9. Start Small, Then Grow
Don’t boil the ocean. Here’s a simple three‑phase plan for Implement RAG in Business Operations at scale:
- Pilot: One team (HR or Sales), 20–30 docs, a handful of real users.
- Refine: Tweak chunk size, metadata filters, prompt style based on feedback.
- Expand: Add more teams, more document types, maybe a multilingual layer.
10. Measure What Matters
Avoid vanity metrics. Focus on real impact:
- Adoption Rate: Percentage of target team using it weekly.
- Helpfulness Score: Ratio of upvotes to total ratings.
- Time Saved: Average drop in time‑to‑answer (use timestamps).
- Ticket Reduction: Fewer manual requests to SMEs.
If adoption stalls or accuracy dips, circle back to chunking or docs cleanup.
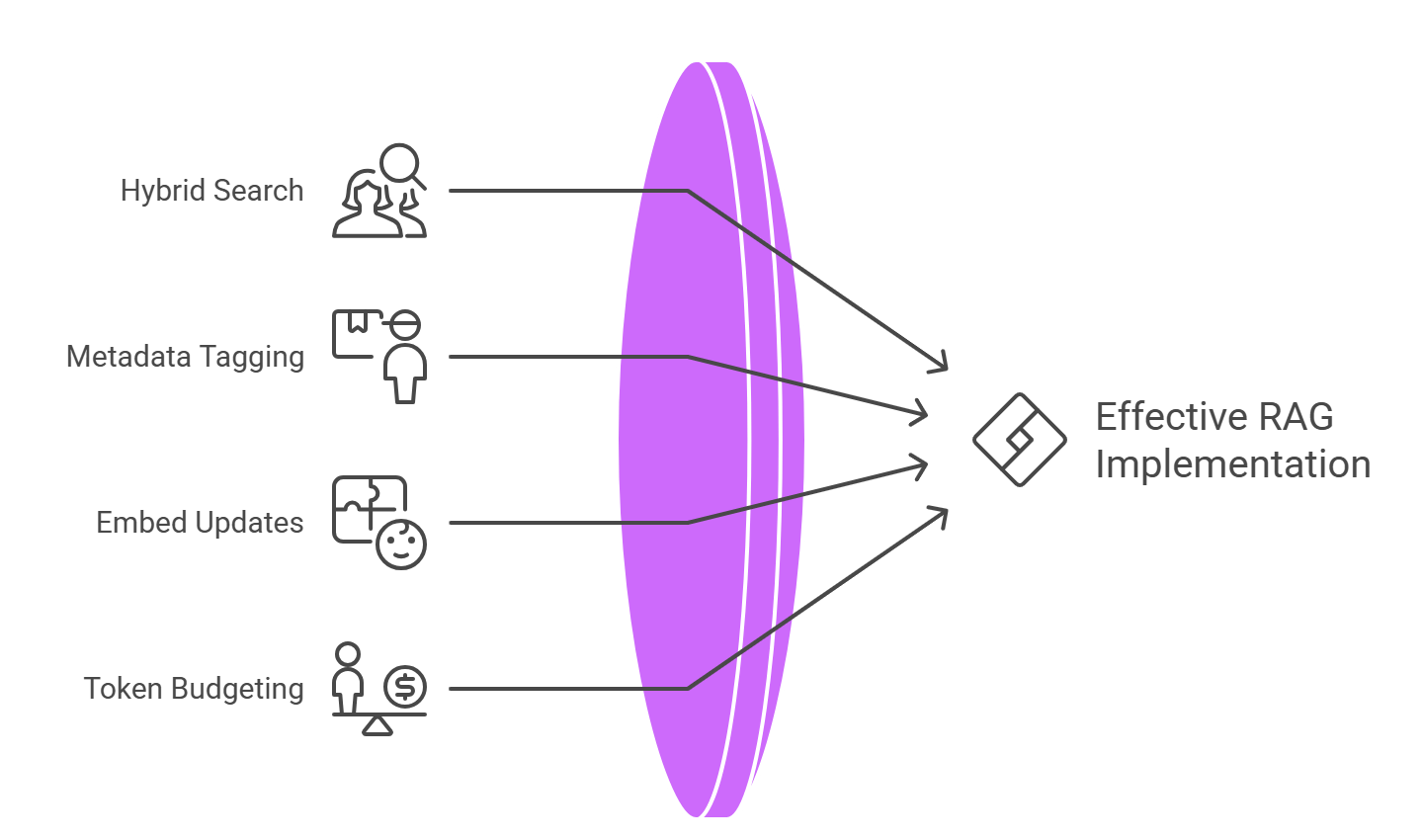
Little Tricks You Won’t Hear at Conferences
- Hybrid Search Wins: Mix simple keyword filters (BM25) with vector search. You get the best of both worlds.
- Metadata Is Your Friend: Always tag by author, date, and department. Without it, you’ll serve up irrelevant, stale info.
- Embed Updates, Not Just Docs: When a document changes, re‑embed only that chunk—don’t rerun your entire corpus.
- Watch Token Budgets: With larger models, you can hit limits fast. Monitor prompt + context length so nothing gets cut off mid‑sentence.
RAG done right keeps your AI honest and your team confident.
Checkout: How Business Intelligence Helps Improve Decision Making
Wrapping Up
Putting RAG in Business Operations into practice isn’t about flashy demos or buzzwords. It’s about solving real work pains:
- Stop the endless searches through shared drives.
- Trust your AI because it’s using your own vetted info.
- Free up experts from answering the same questions day after day.
Start with a clear use case, keep your pipeline lean, and lean on feedback. In a few weeks, you’ll see people turning to your RAG assistant first - because it’s quick, accurate, and actually helpful. That’s how you go from “nice demo” to “can’t live without it.”
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.