4/7/2025

AB
RAG for NL2SQL: Beyond Basics for Enterprise Database Accuracy
Transform your data access with advanced Retrieval-Augmented Generation techniques. Say goodbye to SQL headaches and get insights in plain English today!

Connecting with vast databases for your entire organization, from sales to C-suite, is no longer a dream. For example, you can ask, "Show me our top Q1 enterprise deals in EMEA, broken down by new versus existing customers, and compare their sales cycle length to last year's average." This will eliminate the need for SQL expertise, just plain English.
While Natural Language to SQL (NL2SQL) promises to make data accessible to everyone, the reality is often challenging, especially when dealing with the extensive and often separate database systems common in B2B businesses, such as your CRM, transaction systems, and customer support platforms. Simply using a Large Language Model (LLM) to handle this complexity will lead to frustration, inaccurate queries, and ultimately, a failed project.
For data professionals who want to truly use enterprise data with Generative AI, the solution lies in advanced Retrieval-Augmented Generation (RAG) techniques. This involves creating a smart, flexible system, not just using basic RAG.
Let's explore how to design such a solution using tools like Google's Gemini embeddings and the LangChain SQL toolkit while avoiding common mistakes.
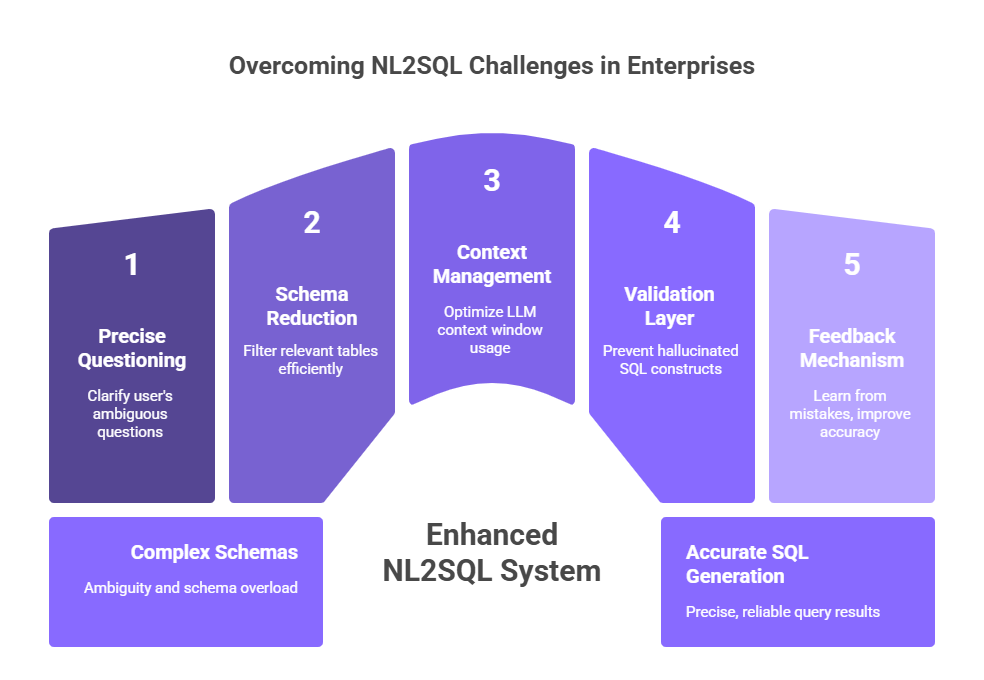
The Main Problem: Why NL2SQL Struggles with Complex Enterprise Systems
Before we start building, let's understand the challenges. If you've tried basic NL2SQL, these will sound familiar:
- Ambiguity is the Enemy: User questions are often unclear. For example, "Top customers"—does this mean by revenue, order volume, engagement score, or lifetime value?
- Schema Overload: Modern businesses can have hundreds or even thousands of tables across multiple databases. Which ones are relevant for "Q1 enterprise deals"? How do they connect?
- Context Window Limitations: LLMs, even powerful ones, have limited memory. Feeding an entire multi-database system is impractical and ineffective.
- The Hallucination Risk: LLMs can confidently create table names, columns, or connection rules that don't exist, resulting in SQL that is grammatically correct but logically meaningless.
- Static Systems Don't Learn: Without a way to get feedback, the system will repeat its mistakes, leading to users losing trust.
These are not just minor technical issues; they are major obstacles to getting a return on investment (ROI) and widespread adoption
Checkout: The Architecture Behind Real-Time Ops Intelligence: RAG + NL2SQL Explained
The RAG-Powered Solution: Smart System Retrieval for Accurate SQL
Retrieval-Augmented Generation (RAG) completely changes the game. Instead of relying only on the LLM's pre-trained knowledge, we first retrieve the most relevant parts of your database system (and other helpful information) and then provide this focused information to the LLM to generate the SQL query.
Imagine it like giving the LLM an open-book exam, but you've already picked out the exact right pages from a huge library for each specific question.
Phase 1: System Intelligence – Smart Grouping and Embedding with Gemini
This is where many NL2SQL projects fail by not taking system preparation seriously enough. Bad input leads to bad output.
The Goal: Create meaningful and easy-to-find "chunks" of your system.
How We Do It (Beyond Basic Column Lists):
- Unified Metadata Layer: Gather all information about your different data sources (Snowflake, Redshift, BigQuery, Postgres, Salesforce, HubSpot, etc.) in one place. Systematically extract table names, column names, data types, and, most importantly, how they relate to each other (foreign key relationships).
- Enhance with Business Context: This is crucial. For each table and important column:
- Add plain language descriptions (e.g., "The customer_activity table logs all customer interactions...").
- Include common business definitions or calculations (e.g., "ARR is calculated as mrr * 12...").
- Document common ways tables are joined and what they mean in business terms.
- Capture example queries or how they are typically used, if available.
- Represent Views/Materialized Summaries as these are very valuable for RAG.
- Embedding with Gemini: Use a strong embedding model like Google's text-embedding-gecko (or similar) to turn these rich text chunks into dense numerical representations (vectors).
- Vector Database Storage: Store these embeddings in a vector database (e.g., FAISS, Chroma, Qdrant, Weaviate, or Pinecone).
- Metadata Tagging is Crucial: Tag each vector with its source (e.g., {"table": "orders", "source_system": "transactional_db", "domain": "sales"}). This allows for filtered searches later.
Mistake to Avoid: Embedding raw lists of table and column names without descriptions, relationships, or business context. This leads to poor retrieval because the embeddings lack meaning.
Phase 2: The Query Engine – LangChain SQL Toolkit as Your Main Tool
LangChain provides excellent building blocks. The SQLDatabaseChain is a good starting point, but for large systems, it needs adjustments.
Key Adjustments:
- Override get_table_info(): This is essential for large systems. Instead of LangChain’s default (which might try to put too much into the prompt), this function should:
- Take the user's natural language query.
- Embed the query using the same Gemini model.
- Perform a similarity search against your vector database of system chunks.
- Retrieve the top-K most relevant system chunks.
- Format these retrieved chunks neatly for inclusion in the prompt.
- SQLDatabaseSequentialChain (If Needed): For queries requiring multiple steps or complex reasoning (e.g., "Which marketing campaigns led to the most signups that then converted to paying customers within 30 days?"), this chain can break down the problem.
Mistake to Avoid: Relying on LangChain's default SQLDatabaseChain to magically handle large systems by including all table information. This will quickly exceed context limits and reduce accuracy. Precise retrieval is crucial.
Checkout: What is Operational Intelligence (OI)? Complete 2025 Overview
Phase 3: Smart Retrieval & Context-Rich Prompt Engineering
Your prompt is where the magic (or chaos) happens.
Retrieval Strategy:
- Embed the user's natural language query using your Gemini embedding model.
- Query your vector database to find the top-K system chunks. Consider also retrieving any example queries or business rules associated with these chunks.
- Optional Reranking: A lightweight reranker model (e.g., a cross-encoder like MiniLM) can reorder these top-K results based on more subtle meaning.
Prompt Design – The Art and Science: A well-structured prompt guides the LLM effectively.
Mistake to Avoid: Creating embedding chunks that mix raw SQL syntax with natural language descriptions too loosely. This can confuse the embedding model.
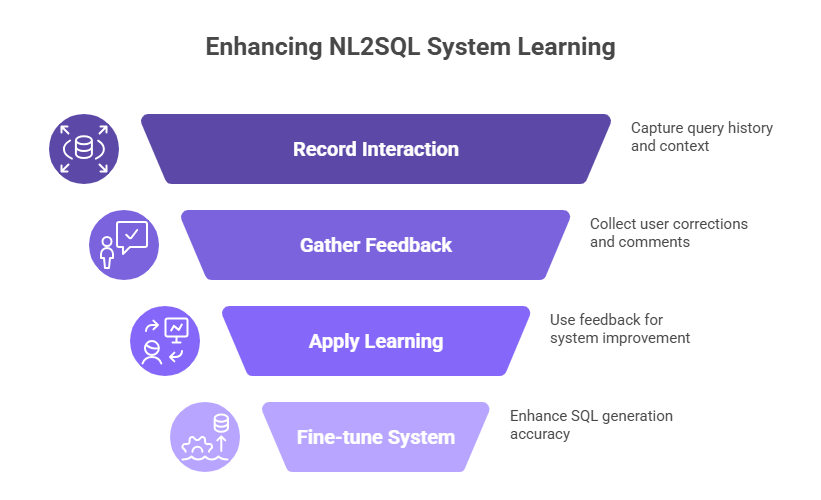
Phase 4: The Learning Loop – Memory & Feedback for Continuous Improvement
A system that generates SQL from natural language questions but doesn't learn is a dead end. Your system must learn.
A. Memory for Context and Fine-tuning:
- Query History: Record every interaction: the natural language question, the retrieved system chunks, the generated SQL, whether it ran successfully or failed, user feedback, and corrected SQL. Store this in a structured database (Postgres, Supabase, etc.). This data set is incredibly valuable for fixing issues and for future fine-tuning.
- Conversational Memory (Short-Term): For follow-up questions ("Now show this for last quarter?"), use LangChain's ConversationBufferMemory or similar. This allows the LLM to remember the recent conversation.
B. The Feedback Loop – The Key to Being Ready for Production: This is where most RAG systems fall short in real-world use.
- User Feedback Mechanism: Provide a simple user interface where users can mark a query as incorrect, submit a corrected SQL query, and add comments.
- Automated Learning from Feedback:
- Positive Reinforcement: Successful, highly-rated queries can be used as examples for future similar queries.
- Negative Feedback/Corrections: Store the combination of (Natural Language Query, Bad SQL, Correct SQL, Context Chunks Used, User Comment). Re-embed and update your vector database: The corrected Natural Language Query-SQL pair can be used to make existing chunks more relevant for similar future queries.
- (Advanced) Fine-tune a Reranker: Use this data to train a model that specifically learns to prioritize the system chunks that lead to correct SQL for similar queries.
Mistake to Avoid: Releasing an NL2SQL system without any way for users to provide corrections or for the system to learn from those corrections. The system will stop improving, and users will stop using it.
Checkout: Choosing the Right Clustering Algorithm: K-Means vs Hierarchical
Phase 5: Handling Different Data Sources (CRM, Transactional, etc.)
Your CRM data (leads, contacts) is different in meaning from your transactional data (orders, payments). The system needs to handle this.
- Source-Aware System Chunking: Tag your system chunks with their source system (crm, erp, web_analytics).
- Intent-Driven Retrieval Bias:
- Lightweight Classifier (Optional): Train a simple program to predict the likely data source based on the natural language query.
- Keyword-Based Rules: Simpler rules can also work initially (e.g., if "customer support ticket" is in the query, prioritize "support_db" chunks).
- Multi-Source Prompting: If a query involves multiple areas (e.g., "Show me customers from our latest marketing campaign who made a purchase over $100"), your retrieval should get relevant chunks from both source systems. The prompt needs to clearly separate these contexts.
Example Query Flow with Multi-Source Context: User: "What was the total order value last month from leads generated by our 'Summer SaaS Promo' campaign?"
- Intent/Source Analysis: Query contains "order value" (transactional) and "leads," "campaign" (CRM).
- Embedding & Retrieval:
- Embed "total order value last month" -> Retrieve orders table schema, payments schema (from Transactional DB).
- Embed "leads generated by Summer SaaS Promo campaign" -> Retrieve leads table schema, campaigns table schema (from CRM DB).
- Prompt Construction: The prompt will include schema snippets from both orders and leads/campaigns. The way a customer_id in orders connects to a lead_id or contact_id needs to be in the retrieved schema context.
Designing for Success: A High-Level Plan
Conclusion: From Fragile Programs to Smart Data Conversations
Building a strong, ready-for-use NL2SQL system for large, mixed enterprise databases is a significant engineering effort. It's much more than just connecting an LLM to a database. By strategically breaking down and enriching your system, using powerful embeddings like Gemini, employing smart retrieval through vector search, designing careful prompts, and most importantly, implementing a continuous learning loop with user feedback, you can move beyond easily broken solutions.
The result? A system that doesn't just answer questions but engages in a meaningful data conversation, enabling your entire organization to make faster, smarter decisions. This is the true promise of Generative AI in the enterprise data world, and with a well-designed RAG approach, it's within your reach.
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.