Table of Contents
Alert Fatigue in Lending Ops: Fixing the Wrong Things First
Stop wasting time on low-impact alerts! Learn how to streamline your operations and focus on what truly matters to prevent regulatory risks in lending.
August 25, 2025

AB

What is alert fatigue in lending operations?
Alert fatigue in lending operations is what happens when the volume of system notifications exceeds a team's ability to meaningfully triage them. When everything is marked critical, nothing effectively is. Teams develop coping patterns, muting channels, skimming alerts, defaulting to the loudest complaint rather than the highest-impact problem, and the exceptions that actually threaten SLA compliance or regulatory standing get missed.
When everything is marked “critical,” teams waste hours fixing the wrong things first
Walk into any lending operations war room and you’ll see the same scene: dashboards glowing red, Slack channels buzzing with alerts, and ops teams frantically chasing down “critical” issues. Yet by the end of the day, the real problem, the one that actually risks SLA breaches or regulatory penalties remains unresolved.
This is alert fatigue. And in lending ops, it’s not just distracting, it’s expensive.
Why this problem matters now
Operations teams are drowning in signals. Security and ops studies show staggering alert volumes: enterprise SecOps receives thousands of alerts daily; academic studies of DevOps workflows show engineers overwhelmed by weekly alert counts where only a minority require direct action.
Meanwhile, data teams the backbone that converts signals into decisions - report that data quality and reliability are top priorities, and many teams are bogged down in “plumbing” rather than delivering impact. That means your alert stream is only as good as the data and wiring behind it.
Put simply: alert noise + brittle data + no business context = missed SLAs, regulatory risk, and burned teams.
In India's BFSI sector specifically, RBI's operational risk circulars and NBFC compliance frameworks have increased the consequence of missed alerts significantly. A mandate presentation failure that sits undetected for 6 hours is a data point; one that sits for 48 hours is a potential compliance event. As digital lending volumes in India grew approximately 40% year-on-year through 2024 (source: Fintech Association for Consumer Empowerment, FACE Annual Report 2024), the alert volume scaling problem has outpaced the growth of ops teams at most mid-tier lenders.
What good and bad alerting looks like (real examples from lending ops)
Bad alerting (severity-first):
- LOS says: “Event: KYC retry failed - severity=critical.”
- Disbursement system says: “Mandate presentation failed - severity=critical.”
- Collections says: “Promised-payment missed - severity=critical.”
All land in the same channel. Ops scrambles, picks low-impact items, high-value SLAs slip.
Good alerting (impact-first):
- Alert #1: “High-value disbursement ₹5.2M - presentation failed; SLA breach possible in 3 hours - owner: Disbursements Lead.”
- Alert #2: “Mandate presentation spike (product X) - retry success rate down 25% vs baseline - investigate bank partner Y.”
- Alert #3: “KYC retry loop - affects 1.2% of incoming apps; projected lost conversions = 4,000/month - owner: Onboarding Ops.”
Each alert is scored, prioritized, owned, and tied to a measurable KPI.
Autonmis’ product materials and pilot approach are purpose-built to create these prioritized operational signals and accountable workflows across origination → disbursal → collections.

Checkout: How Predictive Analytics Improves Operational Efficiency
The core technical fix: an Alert Scoring Model (practical, implementable)
At the heart of impact-first alerting is a reproducible scoring function that converts system events into business-prioritized signals.
1) A concise scoring formula (start here)
Definitions & suggested weights (starter configuration)
- ValueAtRisk - monetary exposure of the alert (e.g., amount of disbursement, revenue at risk) - weight 0.4
- SLA_Urgency_Wt - time-to-SLA-breach factor (e.g., 0.0–1.0 where 1.0 = breach in <1 hour) - weight 0.25
- Likelihood_Wt - probability this event causes downstream failure (modelled from historical data) - weight 0.15
- Compliance_Wt * Compliance_Impact - regulatory sensitivity (e.g., KYC missing for regulated product) - weight 0.15
- Customer_Impact_Wt * Customer_Impact - number of customers or strategic customers impacted - weight 0.05
Use min-max normalisation on monetary figures and timestamps, cap the final AlertScore to 100, and set thresholds:
- 90–100: Immediate Exec/Ops attention (page owner + escalate)
- 70–89: Ops lead workqueue - resolve within SLA
- 40–69: Batch remediation or automated retry
- <40: Monitor / ingest into summary metrics
Why this works: it converts disparate system signals into a single, ranked, business-centric queue — so the team fixes the things that move KPIs and prevent SLA breaches first.
2) A sample SQL snippet to compute a retry-success signal (useful for mandate failures)
Use fail_rate to populate Likelihood_Wt and ValueAtRisk to compute AlertScore.
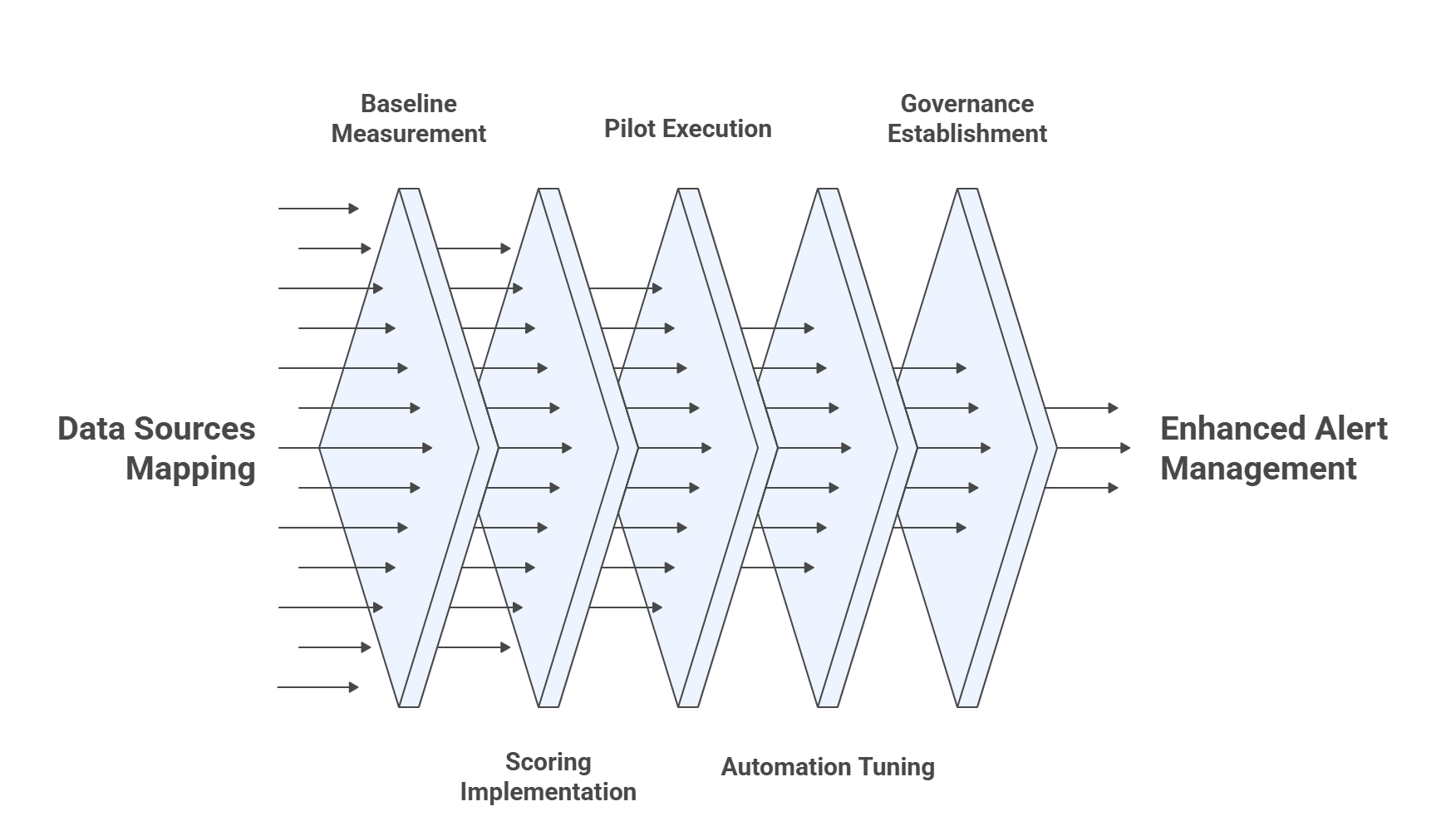
Implementation playbook - 6 practical phases (what I ran in production)
Phase 0 - Discovery (Week 0)
- Map data sources (LOS, disbursement logs, KYC provider, collections CRM). Autonmis’ pilots typically start here (days 0–2).
- Identify top 10 alert types that historically lead to SLA breaches.
Phase 1 - Baseline & Noise Audit (Week 1)
- Measure alert volumes, false positives, and time spent triaging per alert type.
- Compute precision@K for existing alerts where K=50 (how many top alerts are true positives).
Phase 2 - Scoring & Prioritization (Week 2–3)
- Implement the scoring function in the event pipeline (streaming or batch).
- Attach metadata: owner, SLA window, evidence links.
Phase 3 - Pilot (Week 4)
- Run 2-week live pilot on a slice of volume (e.g., disbursements or early collections). Autonmis’ pilots typically ship a leadership MIS pack + 6–10 high-signal alerts in this window.
- Track MTTR, SLA breaches, and ops hours.
Phase 4 - Iterate & Automate (Week 5–6)
- Automate retry flows for low-ValueAtRisk items; keep human-in-loop for high-score alerts.
- Tune thresholds and weights from observed precision/recall.
Phase 5 - Governance (Ongoing)
- Change history, runbook maintenance, audit trails, and scheduled MIS for leadership. Autonmis recommends role-based access and evidence trails for audit readiness.
Checkout: Why Dashboards Don’t Prevent SLA Breaches
Operational rules & playbook (what to enforce immediately)
- Every alert must have an owner - no owner = no action. Route to a person or role. (Automate routing with ownership tables.)
- Attach a resolution SLA to the alert - display countdown clock; escalate automatically when nearing breach.
- Group & deduplicate: if 100 events are the same failure (same bank partner + same failure signature), produce one aggregated alert with a list of representative events.
- Instrument alert quality: track AlertPrecision = ResolvedAsActionable / AlertIssued and AlertRecall = ActionableEventsDetected / TotalActionableEvents. Set targets (precision > 80% first, then improve recall).
- Audit & evidence: every resolved alert must leave a short trace (who, what, when, why, remediation steps) - required for regulatory audits.
Sample escalation matrix (example)
- Score ≥ 95 - Page Ops Lead + SMS to Head of Ops; 1-hour SLA.
- 90–94 - Notify Ops Lead + pop in command queue; 2-hour SLA.
- 70–89 - Routed to queue owner; 6-hour SLA.
- <70 - Batch-process / monitor.
KPIs to prove ROI (what to measure week over week)
- SLA Breach Count (weekly) - target: reduce by X% in pilot.
- MTTR for high-score alerts - median time.
- Ops hours spent on low-value alerts - measure reduction.
- Alert Precision & Recall - see above.
- Cost or revenue at risk recovered - monetise improvements where possible.
Autonmis pilots demonstrate measurable improvements when high-signal alerts and ownership models are deployed. Example deliverables include a Stuck Disbursement Command View, Mandate Presentation Tracker, and leadership MIS.
Common pitfalls and how to avoid them
- Pitfall: Over-complicating the scoring function.
Fix: Start with 3 signals (ValueAtRisk, SLA urgency, failure rate) and iterate. - Pitfall: Pushing more alerts to execs.
Fix: Execs should only see top-N high-impact incidents or a summary with drilldown. - Pitfall: Data-quality blind spots.
Fix: Invest 20% of pilot time in fixing mappings, identity resolution, and timestamp consistency (Autonmis onboarding highlights this phase). - Pitfall: No human ownership.
Fix: Make ownership non-negotiable, escalate unclaimed alerts automatically.
Quick comparison: Severity-first vs Impact-first
- Severity-first alerting ranks notifications by what the system thinks is serious. A KYC retry failure is "critical." A mandate presentation failure is "critical." A stuck ₹5 crore disbursement three hours from SLA breach is also "critical." They land in the same channel, in no particular order, and the ops team works through them based on which complaint arrived loudest. The high-value SLA item gets to them when they get to it.
- Impact-first alerting ranks notifications by what the event actually means for the business. Value at risk, SLA time remaining, regulatory exposure, customer impact. A ₹5.2 crore disbursement failure three hours from SLA breach goes to the top of the queue, routed to the disbursements lead with a countdown clock. A KYC retry affecting 12 low-value applications goes into a batch remediation queue. The team works from the top down, which means the things that matter get fixed first.
- On ownership: Severity-first alerts go to a channel. Nobody owns them until someone decides to pick one up. Impact-first alerts route to a named person. If that person does not act within the defined SLA window, the system escalates automatically.
- On audit readiness: Severity-first alerting leaves no trace of what was actioned, when, or why. Impact-first alerting requires every resolved alert to leave a short record of who acted, what they did, and when. That record is what a regulatory auditor looks at.
- The shift from severity-first to impact-first is not about changing tools. It is about deciding what "critical" means: a system label, or a business consequence.
A compact, ready-to-use checklist (copy-paste into your runbooks)
- Inventory alert sources (LOS, KYC, disbursements, collections).
- Compute baseline alert volumes & triage time.
- Implement AlertScore with ValueAtRisk and SLA_Urgency. (Use SQL snippet above.)
- Route alerts to owners and set escalation rules.
- Run 14-day pilot, track MTTR & SLA breaches. Autonmis pilots typically deliver first dashboards and 6–10 high-signal alerts in this timeframe.
- Tune weights and expand to other pipelines.
Checkout: How to Improve Operational Efficiency in Fintech
Final note leadership & culture
Tools and models matter, but so does culture. The most successful recovery I led combined three things:
- A brutal audit of what alerts actually led to SLA breaches.
- A simple prioritization rule that everyone could read and defend (value × urgency).
- Relentless ownership - making one person accountable for each alert until it’s cleanly closed.
If you can turn alerts into accountable actions and measure whether alerts helped prevent SLA breaches, you’ll move from firefighting to confident operational control.
Frequently Asked Questions
What is the difference between severity-based and impact-based alerting?
Severity-based alerting ranks notifications by how serious a system event is. Impact-based alerting ranks notifications by what the event means for the business — value at risk, SLA time remaining, regulatory exposure, and customer impact. A ₹5.2 crore disbursement failure three hours from SLA breach is more important than a 500-rupee retry failure, regardless of what the system logs call "critical." Impact-based alerting makes this distinction explicit and actionable.
How do you reduce alert fatigue in a lending operations team without missing critical issues?
Three steps that work in practice: first, compute a business-impact score for every alert rather than using system severity alone, the scoring formula in this piece is a starting point. Second, deduplicate, if 100 events share the same failure signature, produce one ranked alert with context, not 100 separate notifications. Third, attach explicit ownership: every alert routes to a named person with an SLA clock. Unclaimed alerts escalate automatically.
What should a good lending operations alert actually contain?
A useful alert in lending ops contains: what happened (the event, not just the status), business exposure (amount at risk, customer tier, SLA time remaining), who owns it (named individual, not just a team channel), what the playbook is (2-4 steps to resolve or escalate), and an evidence trail (logs, timestamps, transaction IDs). An alert that contains only "KYC retry failed - severity: critical" requires the recipient to gather all of that information themselves before they can act.
How do you prove the ROI of fixing alert fatigue to leadership?
Four numbers tell the story: SLA breach count before and after the change, MTTR (mean time to resolve) for high-score alerts, hours per week the ops team spent on manual triage before and after, and regulatory or penalty exposure avoided. Measure these weekly during the pilot. The ROI of a lending ops team that catches a ₹5 crore SLA breach two hours before it closes rather than two hours after is not a conceptual argument, it is a number.
Recommended Blogs

5/4/2026
Abhranshu
The Data to Decision Gap: What It Costs and Why It Exists

4/16/2026
AB
How to Preserve Institutional Knowledge in Data Workflows
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.