Invalid Date

AB
What Is SLA Monitoring and Why Is It Important?

When a client signs your contract, they are purchasing a promise - a quantifiable assurance that a business outcome will occur within predetermined parameters - rather than a service. The Service Level Agreement (SLA) is that guarantee. SLA monitoring is the ongoing process of assessing whether those commitments are being fulfilled, converting unprocessed telemetry into business signals, and taking action before a failure turns into an expensive violation.
Consider SLA monitoring as a risk-management and revenue-protection function rather than just another dashboard for engineers.
The simple definition
Uptime, response time, throughput, transaction settlement times, resolution times, and other quantifiable commitments are all included in a SLA. SLA monitoring creates context-rich alerts, calculates SLOs, instruments those commitments, and generates auditable evidence for billing, audits, and dispute resolution. In other words, monitoring transforms contractual language into signals that can be repeated and verified.
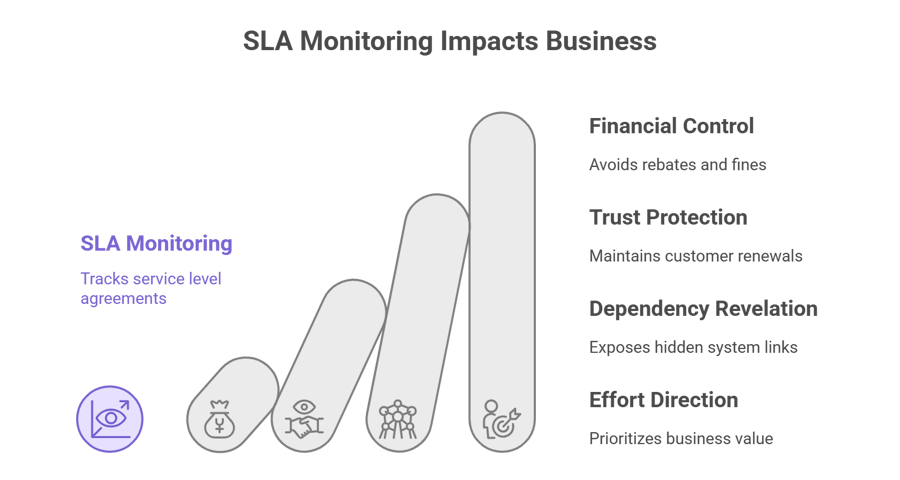
Why SLA monitoring matters
1) It’s a financial control
Rebates, fines, lost renewals, and reputational harm are all real costs associated with missed SLAs, sometimes exceeding the engineering work necessary to avoid them. Months' worth of margin can be lost in a single high-value breach.
2) It protects trust and renewals
Impact, not metrics, is what users remember. Trust is destroyed more quickly by a brief outage that disrupts important customer workflows than by a comparable period of reduced but non-blocking performance.
3) It reveals hidden dependencies
Instead of just "our code," the majority of breaches are linked to third-party APIs, data inconsistencies, or integration flaws. In order to address the underlying cause, effective monitoring reveals cross-system causality and dependency health.
4) It directs engineering effort to business value
Errors are not all created equal. SLA-driven prioritization concentrates limited engineering cycles on factors other than infrastructure noise that put you at risk of financial loss or customer attrition.
Checkout: Top 6 Ways AI Is Transforming Business Operations
What mature SLA monitoring actually measures
Go beyond a single "uptime" figure. Five layers make up a robust monitoring program
- Service health: availability, error rates, latency percentiles (p50/p95/p99), and service health.
- Business KPIs: revenue-impact metrics, settlement latency, and transaction completion rate.
- SLO windows and thresholds: the proportion of events that are finished within SLA windows (e.g., 99.5% of payments settled within 3s).
- Process metrics: missing metadata, reconciliation errors, and queue depths.
- Dependency health: contract renewal dates, cert expirations, and third-party API latency.
Technical events can be mapped to business impact by measuring at these layers.
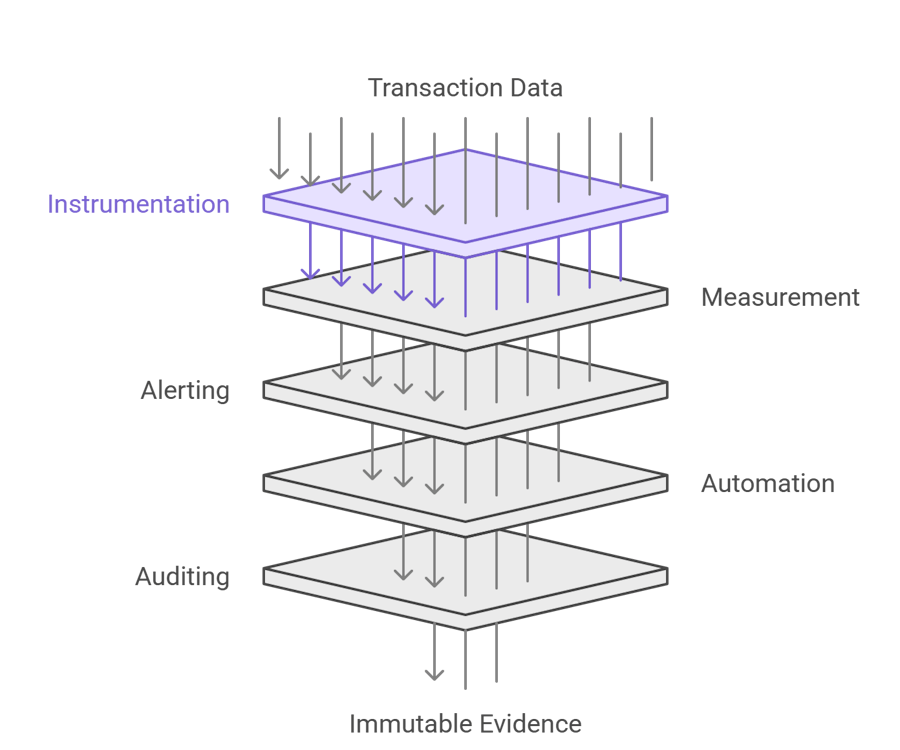
Practical architecture - how to build it
1. Instrumentation
Add business metadata (customer, contract id, value, SLA tier) to each transaction. Telemetry is useless for SLA enforcement if it cannot be linked to a contract.
2. Measurement
Convert events into SLO computations and time-series metrics (windows, percentiles, and error ratios). Preserve both aggregated SLO views and raw events.
3. Alerting with business context
Affected customers, contract exposure (estimated penalty), business priority, and recommended action must all be included in alerts. KPI-first alerts are superior to severity-first ones because a batch delay that results in penalties is not the same as an infra P1 that affects no contract.
4. Automation and playbooks
A short runbook and an automated escalation path (ops → on-call → finance/legal if exposure exceeds a threshold) should be linked to each alert.
5. Auditing & immutable evidence
Save SLA computations and event logs for audits and dispute settlement. This eliminates the use of "he said/she said" in discussions that follow an incident.
Checkout: What is Operational Intelligence (OI)? Complete 2025 Overview
KPI-first alerting: a simple rule to adopt today
A lot of teams use severity labels (P1, P2) by default. Use a KPI-first rule in place of or in addition to that: calculate contract exposure per incident (customer value × penalty rate × breach window) and route alerts according to exposure thresholds. As a result, there is less noise and on-call decisions regarding business risk are made precisely.
Short example: lending operations
If "SME loan disbursements must settle within T+1" is stated in your SLA:
- Add the product/customer ID and anticipated settlement window to every disbursement.
- Calculate the value of breaches and the percentage completed within T+1.
- Fixes for breaches should be prioritized based on their financial impact rather than the total number of incidents.
- Automate customer notifications and compensation with playbooks.
This keeps engineers' attention on protecting revenue rather than battling low-impact alerts.
Final thought
Installing SLA monitoring is a continuous process. The combination of instrumentation, business context, and governance constitutes an organizational capability. It becomes your early warning system for revenue and reputation risk when it's integrated into your operations; it's the difference between scaling smoothly and scrambling after every launch.
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.