8/1/2025

AB
What Is Data Ingestion? A Practical Guide
Before AI, before ML, before insights - there’s ingestion. And if you’re not doing it right, nothing else matters.

Whether you’re leading a startup building your first analytics stack, or you're at an enterprise scaling machine learning across business units, data ingestion is the invisible engine that powers everything downstream. It’s often ignored, sometimes duct-taped, and rarely optimized - but when it breaks, dashboards fail, reports lag, and decisions suffer.
In this article, we’ll answer boldly What Is Data Ingestion, walk through the Data Ingestion Process, explain Why Data Ingestion Matters, and share concrete tactics for building bulletproof pipelines.
First, What Is Data Ingestion?
Data ingestion is the process of moving data from its original source into a centralized destination like a data warehouse, lakehouse, or analytics platform, where it can actually be used.
You might see it defined more formally, but at heart it’s this straightforward: grab raw, scattered data from wherever it lives and land it in one place.
Sources include:
- Production databases (Postgres, MySQL, SQL Server)
- SaaS APIs (Salesforce, Stripe, Google Analytics)
- Event streams (Kafka, Kinesis, Pub/Sub)
- Files in S3/GCS (CSV, JSON, Parquet)
- IoT devices and sensors
Destinations typically are:
- Data lakes (AWS S3, Azure Data Lake)
- Data warehouses (Snowflake, BigQuery)
- Real-time stores
Pro Tip: Keep ingestion lightweight: only basic parsing or validation here. Leave heavy transformations for later in your ELT flow.
What Ingestion Isn’t
Let’s be clear. Data ingestion isn’t:
- Cleaning: You might check for schema validity or nulls, but deep transformation is handled later (usually in your dbt layer or notebook).
- Modeling: No joins, no business logic here.
- Reporting: Ingestion just gets data to the warehouse. Visualization happens after.
This is a "just get the data in, reliably" layer.
Checkout: What Is an Operational Data Platform? Complete Guide
Inside the Data Ingestion Process
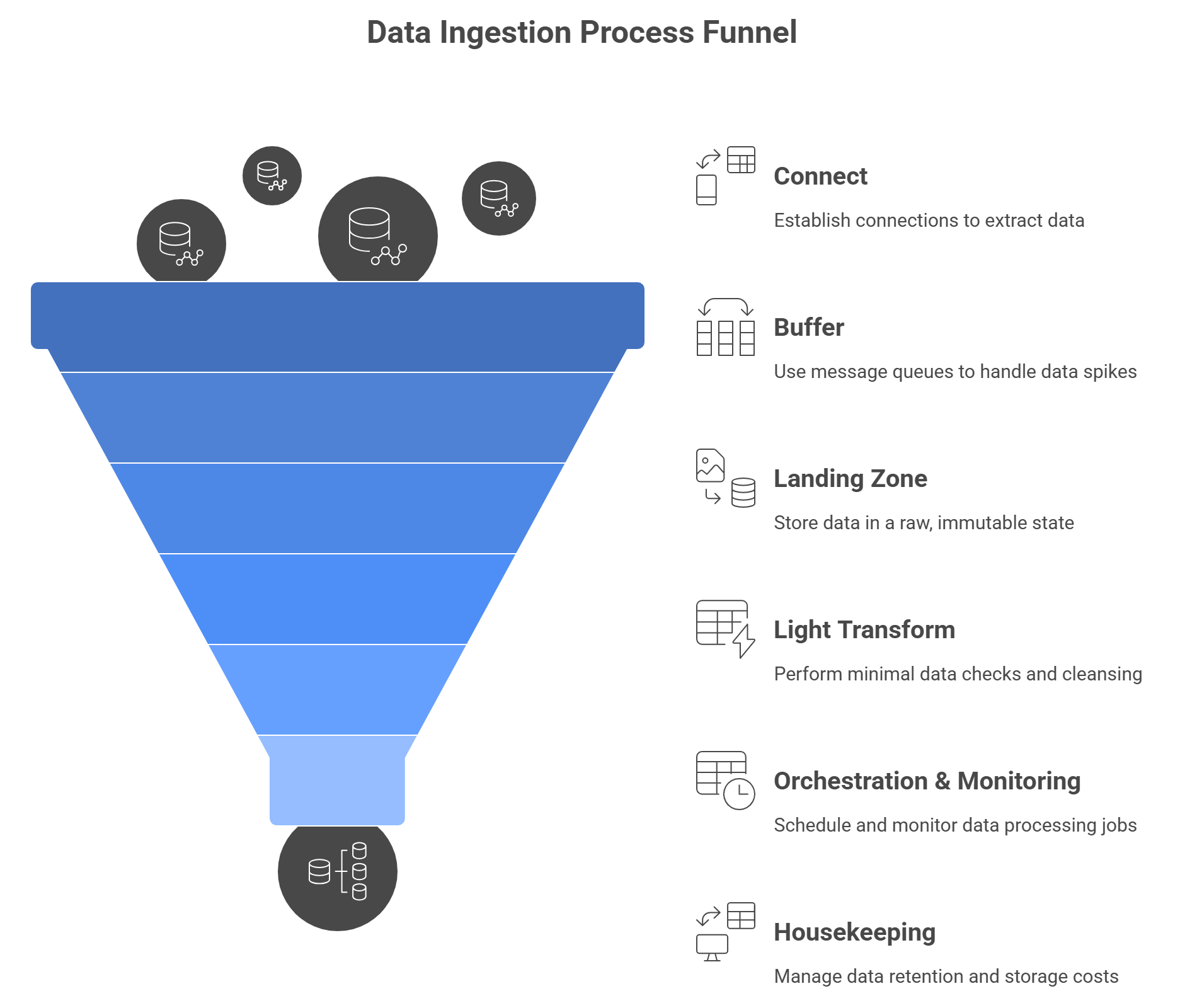
The Data Ingestion Process breaks down into a few clear stages:
- Connect
Use connectors or scripts to extract data from sources. Open-source tools and managed services both work - choose based on your team’s skills and SLAs. - Buffer
To handle spikes and decouple systems, push raw events into a message queue (Kafka, AWS Kinesis, Google Pub/Sub). - Landing Zone
Store untouched data in a “raw” area (e.g., Parquet files in S3 or GCS). This gives you an immutable audit trail and the ability to replay data if needed. - Light Transform
Run minimal checks: schema validation, null or type enforcement, very simple cleansing. Then bulk-load into your warehouse or lake. - Orchestration & Monitoring
Schedule and monitor jobs with Airflow, Prefect, or Dagster. Track key metrics - rows processed, latency, error rates and alert on failures or backlogs. - Housekeeping
Rotate old raw files, manage retention, and ensure cost-effective storage and compute usage.
Follow these steps and you’ll have a repeatable, observable pipeline that scales.
Checkout: How to Improve Business Operations: A Practical Guide
Why Data Ingestion Matters
- Faster Decisions
Waiting hours or days for data to show up means slower reactions. Whether it’s spotting a sudden drop in sales or catching a fraud attempt, quick ingestion means you see problems (and opportunities) sooner. - Clean Data, Less Headache
The moment you pull data in, you get a chance to spot errors, broken fields, missing values, duplicates. Catching those early saves your team from chasing ghosts later. - Control Your Costs
Every API call, every gigabyte stored or moved, costs money. A trim, well-tuned ingestion process keeps bills down. - Scale Smoothly
If your system chokes when traffic spikes (say, Black Friday or a big product launch), you lose money and reputation. A good ingestion layer can handle swings in volume without falling over.
Batch vs. Streaming: What’s the Difference?
Batch Ingestion
- Runs on a schedule: every hour, every night, whatever you choose.
- Great for reports that don’t need to be up-to-the-minute.
- Easier to set up and reason about.
Streaming Ingestion
- Moves data continuously as it arrives.
- Ideal for real-time alerts, live dashboards, fraud detection.
- A bit more complex, but gives you fresh insights by the second
Most teams start with batch. Once you’ve got a handle on that, you can add streaming for your highest-priority data.
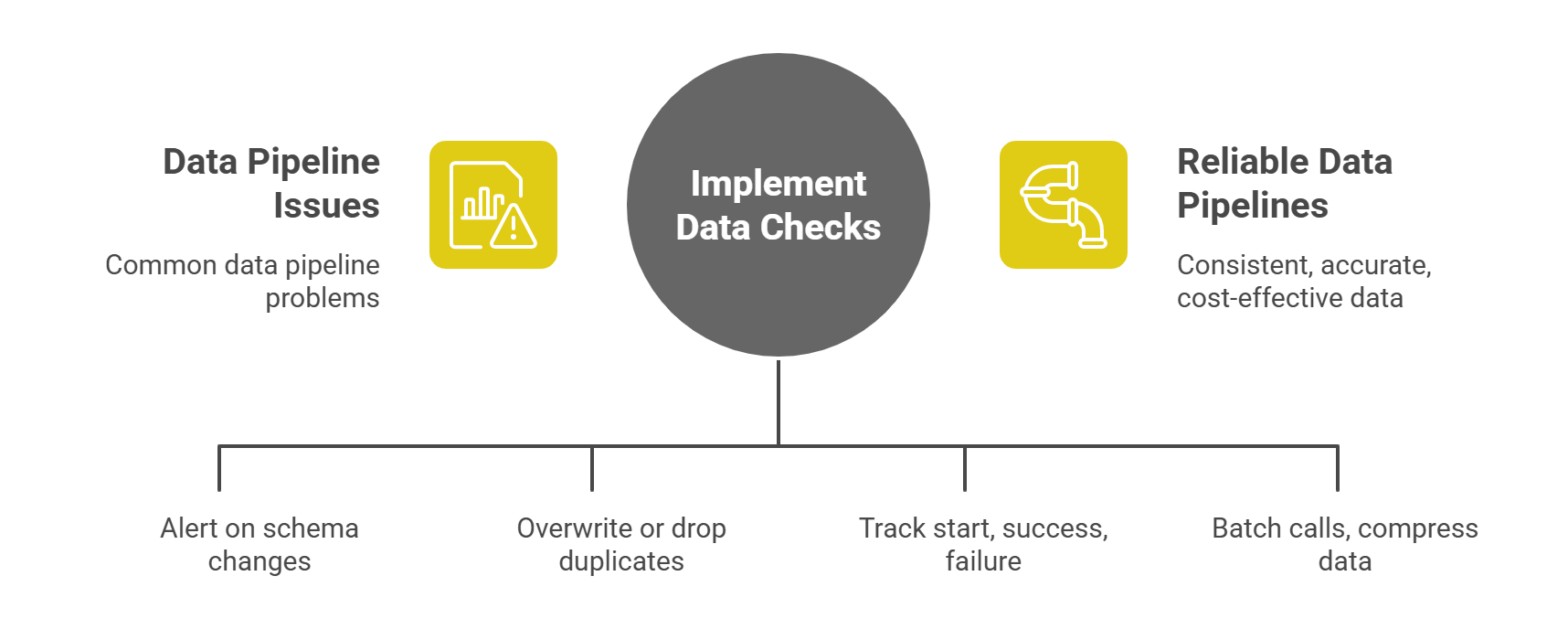
Common Challenges in Data Ingestion and How to Tackle Them
Changing Schemas
Problem: One day your customer table has “phone_number,” the next day it’s “phone.”
Fix: Use a simple schema checker that alerts you when fields change.
Duplicate Records
Problem: Retries and hiccups load the same data twice, skewing your numbers.
Fix: Build your loads to be idempotent - either overwrite by a unique key or drop duplicates as you load.
Hidden Failures
Problem: A job quietly fails and no one notices until dashboards go blank.
Fix: Log every job’s start, success, and failure. Hook those logs into your alerting system.
Unexpected Costs
Problem: API rate limits or cloud egress charges blow your budget.
Fix: Monitor your usage closely. Batch small calls together and compress data when possible.
Checkout: Data Pipeline Architecture Explained: Best Practices 2025
Quick Best Practices
- Idempotency: Ensure each load can run more than once without creating duplicates.
- Schema Checks: Automate alerts on unexpected changes in field names or types.
- Light Validation Only: Don’t turn ingestion into transformation, keep it fast.
- Observability by Default: Collect metrics (records processed, runtimes, errors) and log them.
- Cost Monitoring: Track your cloud and API usage so surprises don’t blow your budget.
Real-World Examples
- E-commerce Dashboard
An online retailer batched daily sales and inventory data into Redshift each morning. By adding streaming for order events, they built a live dashboard that cut out-of-stock incidents by 30%. - Financial Fraud Alerts
A fintech company used Debezium to capture every change in their transactions database. With Kafka streaming those events to a real-time analytics engine, they detect suspicious patterns within seconds. - IoT Device Monitoring
A smart-home vendor ingests sensor readings in real time via AWS Kinesis. When a device reports odd temperature spikes, they push alerts to a monitoring console so engineers can investigate immediately.
Taking It Forward
- Audit Your Pipelines
Map out where data comes from, how it moves, and where it lands. Spot weak links (slow jobs, silent errors). - Automate Alerts
Make sure every failure pings Slack or email. No silent drops. - Plan for Scale
Identify your “hot” data, what needs to be real-time and start with a batch for the rest.
With clear ingestion processes in place, you’ll spend less time wrestling data and more time turning it into insights. And that’s the real goal.
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.