Table of Contents
How to Preserve Institutional Knowledge in Data Workflows
Discover how capturing institutional knowledge in data workflows enhances team speed, consistency, and trust. Avoid pitfalls when key members leave.
April 16, 2026

AB

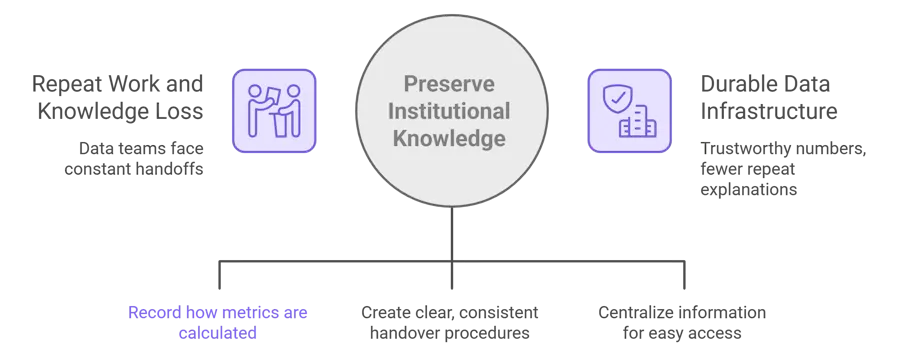
Institutional knowledge in data workflows is the context people carry in their heads about how data really works: what a metric means, why a filter exists, which table is the source of truth, and which caveat makes a number trustworthy. When that knowledge is not captured, the team loses speed, consistency, and confidence every time someone leaves or a workflow changes.
Data teams feel this every day. The docs describe a world where analysts spend much of their time answering the same questions, fixing broken reports, and carrying logic that nobody else can see. When that knowledge stays in one person’s head, the company becomes dependent on that person being available.
Why institutional knowledge disappears so easily
Most data workflows are built to produce outputs, not preserve context. A report gets delivered, a dashboard gets rebuilt, a pipeline gets patched, and the actual reasoning behind it lives in Slack threads, old tickets, or someone’s memory. Over time, that creates a fragile system where the team can keep working, but only because one or two people remember how everything fits together.
The risk becomes obvious when someone leaves. The new person spends weeks reconstructing definitions that used to take seconds to explain. Reports start coming back slightly different. Meetings get spent debating the number instead of using it. The business keeps moving, but trust quietly declines.
What gets lost
The most valuable knowledge in data work is usually not the query itself. It is the surrounding context:
- why a join is written a certain way,
- why a column cannot be trusted before a certain date,
- which records are excluded from a metric,
- which report should be treated as authoritative,
- and what changed when the business logic was updated.
That context is what makes numbers consistent. Without it, the same metric can drift across reports even when everyone is acting in good faith. The product docs call this out clearly: when definitions are not governed, teams end up with different plausible answers to the same question.

Checkout: How to Monitor SLA Breaches in Real Time
What it actually means to preserve knowledge
Preserving institutional knowledge does not mean writing long documentation that nobody reads. It means moving critical context out of people’s heads and into systems that stay with the work.
A preserved workflow should let a new analyst, ops lead, or engineer understand:
- what the metric means,
- where the data came from,
- how the logic was applied,
- who owns the definition,
- and what changed over time.
In other words, the knowledge should travel with the workflow, not sit beside it. In practice, this is the difference between a metric definition living in someone’s notes and living inside the system that runs the metric. Autonmis is one example of that approach: the workflow carries the definition, caveats, ownership, and version history with it.
How to preserve institutional knowledge in data workflows
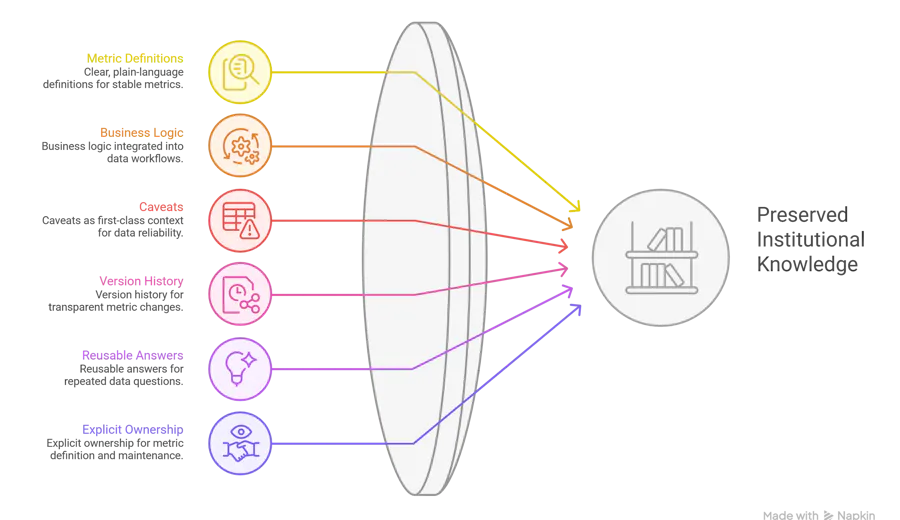
1. Put metric definitions in one governed place
Every important metric should have a plain-language definition, not just a query. If the company cannot explain what a number means in business terms, the number is not stable enough to rely on. Your docs describe this as a governed metric: a metric with an agreed definition, logic, ownership, and version history.
2. Store business logic where the workflow runs
If the rule only exists in a person’s head, it is not part of the system. The business logic should live next to the data asset, SQL, transformation, or dashboard it affects. That way the next person does not have to guess why a filter exists or why a table is handled differently after a certain date.
3. Write caveats down as first-class context
Most data problems are not caused by missing data. They are caused by missing context. If a column is unreliable before a certain timestamp, that caveat should be visible wherever the metric or dataset is used. The docs emphasize that analysts often carry these caveats in their heads, which makes them a single point of failure.
4. Version changes instead of overwriting history
Knowledge gets lost when changes are made quietly. A metric that used to mean one thing and now means another should not just be edited in place. It should have a visible version history, with a reason for the change. That is what keeps people from looking at a report six months later and wondering why the number no longer matches last quarter.
5. Turn repeated questions into reusable answers
If the same question keeps coming back from ops, leadership, or finance, it should not be answered from scratch each time. The answer should become part of the workflow: a definition block, a knowledge base entry, a governed FAQ, or a standard business rule. The docs describe this as moving from tribal knowledge to institutional knowledge.
6. Make ownership explicit
When ownership is unclear, knowledge is fragile. Someone should own the metric definition, someone should own the logic, and someone should know when the definition changes. Without that, the team can have a report but no confidence in who maintains the truth behind it.
7. Build observability into the workflow
Preserving knowledge is not only about documents. It is also about making the workflow visible. If a pipeline fails, if a source changes, or if an exception appears, the system should surface that context early. The problem space docs describe the current state as one where teams often find out too late because humans are still the bridge between data and action.
Checkout: The Future of Business Operations: From Firefighting to AI-Driven Flow
What this looks like in practice
A strong data workflow has three layers:
The logic layer
What the metric means, how it is calculated, and what rules apply.
The knowledge layer
Why the logic exists, what changed over time, and what caveats matter.
The operational layer
Who owns it, how it is monitored, and how exceptions get surfaced.
When all three layers exist, the company stops depending on memory. The workflow becomes teachable, maintainable, and much easier to hand over.
The biggest mistake teams make
The biggest mistake is assuming documentation alone solves the problem.
A folder full of notes does not preserve institutional knowledge if nobody can find it, trust it, or know when it is outdated. The knowledge has to be embedded into the workflow itself. That is the difference between writing things down and actually preserving them.
A simple test
Ask these questions about any important data workflow:
- Could a new person understand this without asking the original builder?
- Would the report still make sense if the author left tomorrow?
- Are the caveats visible where the metric is used?
- Is the definition versioned and owned?
- Can the business stand behind the number in a meeting?
If the answer to any of these is no, the knowledge is still trapped in people.
Why this matters for data teams
Data teams do not just need faster reporting. They need work that compounds. The docs repeatedly point to the problem of repeat work, constant handoffs, and knowledge that resets every time a person changes. Preserving institutional knowledge is what turns data work from temporary effort into durable infrastructure.
That matters for the analyst who wants to stop explaining the same metric for the tenth time, for the engineer who wants fewer fragile handoffs, and for the leader who wants numbers they can trust without a second conversation.
Checkout: Top 6 Ways AI Is Transforming Business Operations
Closing thought
Institutional knowledge should not be a memory test for the person who built the workflow. It should be part of the workflow itself. When that happens, the team stops rebuilding the same understanding over and over, and data starts behaving like infrastructure instead of folklore.
Frequently asked questions
What is institutional knowledge in data workflows?
It is the context behind the data: metric definitions, business rules, caveats, ownership, and the reasoning that makes a number trustworthy.
Why does institutional knowledge disappear?
Because it often lives in people instead of systems. When work is fragmented across reports, Slack messages, and individual memory, the context disappears when the person leaves or gets pulled into other work.
How do you preserve it?
By governing metric definitions, versioning logic, documenting caveats, making ownership explicit, and embedding the knowledge into the workflow rather than storing it separately.
Why is this important for AI and automation?
Because AI systems can only be as reliable as the context they use. If the business logic is unclear or scattered, AI can generate plausible but wrong outputs. Governed, preserved knowledge makes automation safer and more auditable.
Recommended Blogs

5/4/2026
Abhranshu
The Data to Decision Gap: What It Costs and Why It Exists

3/12/2026
AB
How to Monitor SLA Breaches in Real Time
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.