1/30/2025

AB
How to Automate ETL Failures Using an AI Data Platform
Automating ETL failure detection and recovery using an AI data platform like Autonmis can drastically reduce downtime, improve reliability, and eliminate manual firefighting. With built-in anomaly detection, intelligent retries, and self-healing workflows, your pipelines become smarter, faster, and nearly failure-proof.

Efficient, reliable ETL pipelines are the backbone of modern analytics and AI. Yet, according to industry research, around 30% of data integration projects fail to meet their objectives - often due to cascading job dependencies, schema drift, or transient infrastructure issues. Worse still, the mean time to recovery (MTTR) for failed ETL jobs can stretch into hours, delaying critical insights and costing enterprises up to $5,000 per minute of downtime. Automating failure detection and remediation isn’t just “nice to have”- it’s a competitive necessity.
Why ETL Failures Happen (and Why Manual Fixes Don’t Scale)
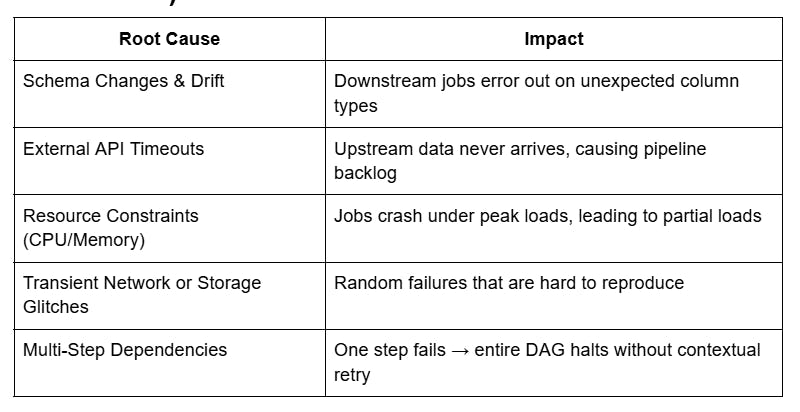
- Manual monitoring and log-scouring can’t catch subtle anomalies in real time.
- Basic retry policies (e.g., fixed back-off) often either retry too aggressively or not enough, failing to distinguish between a permanent schema error and a fleeting network hiccup.
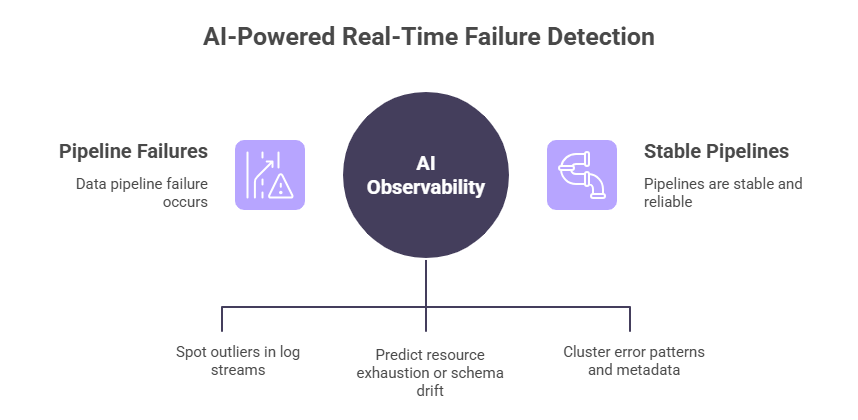
Real-Time Failure Detection with AI
Modern AI data platforms bring continuous observability to your ETL:
1. Anomaly Detection on Logs
Machine-learning models analyze log streams to spot outliers - e.g., an unexpected surge in “NULL value” exceptions - before they cascade into full pipeline failures.
2. Predictive Failure Forecasting
Time-series forecasting predicts resource exhaustion or schema drift events by learning from historical job metrics.
3. Automated Root-Cause Analysis
AI clusters error patterns and metadata to pinpoint if failures stem from bad data vs. configuration issues, reducing investigation time by 80%.
Checkout: What is an AI Data Platform and How Does It Work?
Self-Healing Pipelines: Automated Remediation Techniques
Once a failure is detected, an AI data platform can self-heal your ETL pipelines:
Intelligent Retries with Context
- Airflow’s sensor automatically waits for the correct upstream condition, applying exponential back-off on retries.
- Dynamic Resource Scaling
AI adjusts compute (e.g., upscaling Spark executors) in real time when memory constraints are forecasted, preventing OOM crashes. - Schema-Drift Handling
When a new column appears, the platform auto-infers its type and regenerates the transformation logic - <1% of engineers know this can be done without manual code changes by leveraging embedding-based schema matching. - Automated Rollback & Replay
Failed loads can trigger a rollback of partial writes, followed by a selective replay of only the affected partitions, slashing MTTR from hours to minutes.
Insider Insight: Cross-System Correlation for Ultra-Early Warnings
Fewer data teams leverage external event correlations - for example, tying cloud-provider incident dashboards to ETL job health. By ingesting API feeds from AWS Health or Azure Service Health, an AI data platform can preemptively pause or reroute jobs before provider-level outages impact your pipelines. This edge-case handling can eliminate up to 40% of “mystery” failures, an advanced tactic few competitors offer.
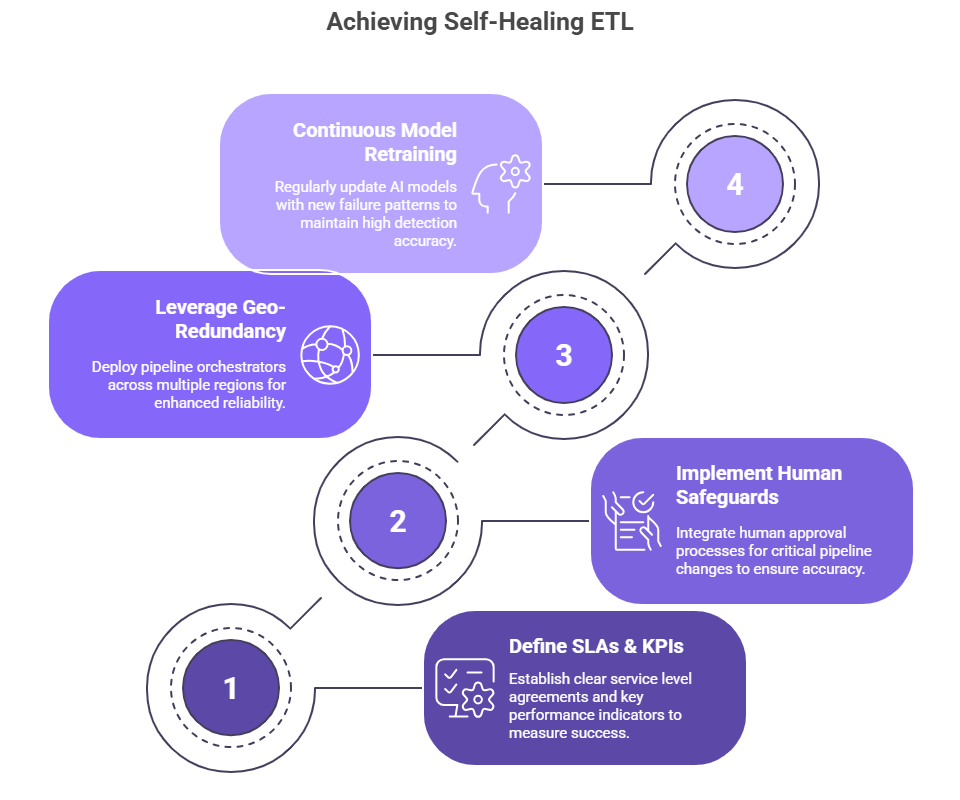
Best Practices for Deploying Self-Healing ETL
- Define Clear SLAs & KPIs
Track MTTR, retry success rates, and anomaly-detection precision. - Implement Human-In-Loop Safeguards
For critical pipelines, require human approval for schema-drift changes. - Leverage Geo-Redundant Architectures
Deploy pipeline orchestrators across regions (e.g., Mumbai & Singapore) for businesses operating in India and APAC markets. - Continuous Model Retraining
Feed new failure patterns back into your AI models to maintain detection accuracy above 95%.
Checkout: What is an AI Data Engineer and How Do They Work?
FAQ
Q: How much downtime can I prevent?
In live deployments, organizations report 82% reduction in downtime with AI-driven self-healing, achieving 99.999% availability.
Q: Which AI techniques power failure detection?
A mix of time-series forecasting (e.g., Prophet), anomaly detection (Isolation Forest), and LLM-assisted log parsing for root-cause analysis.
Q: Do I need custom code?
No - modern AI data platforms provide low-code/no-code hooks. When needed, you can embed your Python or SQL snippets without managing infrastructure.
Conclusion: Let Your Pipelines Take Care of Themselves
Let’s be honest - debugging failed ETL jobs at odd hours isn’t just frustrating, it’s a time sink that slows everything else down. The good news? You don’t have to keep fixing things manually. With the right AI data platform, your pipelines can now detect what’s about to go wrong, fix themselves when it does, and learn from it over time.
Automating ETL failure management with an AI data platform transforms outages into non-events - boosting reliability, speeding time to insight, and freeing your data team to focus on innovation. Ready to build truly self-healing pipelines? Explore Autonmis today!
Recommended Learning Articles
5/30/2026
AB
Why the Same Metric Looks Different Every Time

4/9/2026
AB
What is a governed metric?
Actionable Operations Excellence
Autonmis helps modern teams own their entire operations and data workflow — fast, simple, and cost-effective.